在企业级应用中,服务连续性直接影响业务稳定性和用户体验,高可用集群技术正是保障服务不中断的核心手段。Keepalived作为一款轻量且高效的高可用工具,常与Nginx、LVS等服务搭配使用,构建可靠的集群架构。本文将从基础概念入手,逐步拆解Keepalived原理,结合两大实战案例,带你从零搭建高可用集群。
高可用集群基础认知
什么是高可用集群
高可用集群(High Availability Cluster,简称HA Cluster),是指以减少服务中断时间为目的的服务器集群技术。它通过保护用户的业务程序对外不间断提供的服务,把因软件、硬件、人为造成的故障对业务的影响降低到最小程度。
高可用集群的衡量标准
高可用集群的核心价值,在于保障业务服务的连续性,其核心能力主要体现在自动侦测与自动故障转移两大关键维度:
- 自动侦测:对集群内各节点的运行状态进行实时监控,覆盖硬件健康度、服务进程状态等核心维度,能够精准识别并捕捉各类故障隐患,为故障快速处置提供前置判断依据。
- 自动故障转移(FailOver):当主节点故障被检测到后,无需人工介入,备节点可自动接管主节点的全部服务与资源,实现服务无感知切换,确保用户访问流程不受中断影响。
在实际业务场景中,要让集群服务实现 100% 的永久无间断可用,几乎是难以达成的目标。例如淘宝在历年双十一购物节初期,短时间内海量访问请求集中涌入,曾出现过下单后无法正常支付等服务异常情况。因此高可用集群的设计核心,是尽可能提升服务的有效可用时长;当然在部分业务复杂度低、访问量平稳的特殊场景下,服务的 100% 可用仍具备实现可能性。
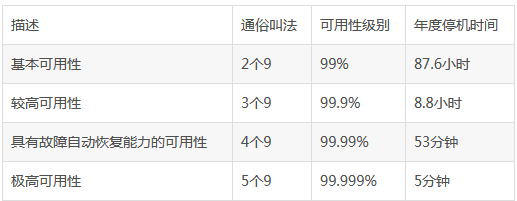
行业内有统一的量化指标来评估高可用集群的性能:以平均无故障时间(MTTF:Mean Time to Failure) 度量系统的可靠性,以平均故障恢复时间(MTTR:Mean Time to Restoration) 度量系统的可维护性。基于这两个指标,系统可用性(HA)的计算公式被定义为:HA=MTTF/(MTTF+MTTR)×100%
自动侦测
自动侦测阶段由主机上的软件通过冗余侦测线,经由复杂的监听程序,逻辑判断,来相互侦测对方运行的情况。 常用的方法是:集群各节点间通过心跳信息判断节点是否出现故障。
脑裂问题解析与解决方案
脑裂简介
脑裂(Split-Brain)是主备架构高可用集群中典型的故障场景,特指主备节点因网络中断等问题导致心跳通信链路失效,双方无法感知彼此运行状态,进而互判对方已宕机,各自抢占主节点角色形成双主冲突,最终引发数据不一致、服务逻辑混乱等严重问题。 在高可用(HA)系统中,主备节点间用于感知对方状态的通信链路被称为“心跳线”,是保障集群一体化协同工作的核心通道。当该链路断开时,原本统一调度、动作协调的HA系统,会直接分裂为两个完全独立的节点个体。 由于相互失去状态感知,两个节点的HA管理软件会同时误判对方发生故障,如同“裂脑人”一般发起资源与服务的争抢:要么集群共享资源被双方瓜分抢占,导致两端的应用服务均无法正常启动;要么两端服务均强行启动,且同时对集群共享存储进行读写操作,最终造成核心数据损坏,其中数据库联机日志因被轮询写入而出错,是此类故障中最常见的表现形式。
脑裂产生的原因
因心跳线坏了(包括断了,老化)。 因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)。 因心跳线间连接的设备故障(网卡及交换机)。 因仲裁的机器出问题(采用仲裁的方案)。 高可用服务器上开启了 iptables防火墙阻挡了心跳消息传输。 高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败。 其他服务配置不当等原因,如心跳方式不同,心跳广插冲突、软件Bug等。
脑裂的常见解决方案
针对脑裂问题,需从“预防”和“兜底”两方面入手,常见方案如下:
冗余心跳线:部署多条独立心跳链路(如双网卡、跨交换机连接),降低网络中断概率,避免单一链路故障引发脑裂。
磁盘锁机制:借助共享磁盘的排他锁特性,确保同一时间仅一个节点能获取锁并成为主节点,从物理层面杜绝双主。
第三方仲裁:引入仲裁节点(或仲裁设备),当主备通信中断时,由仲裁者投票决定有效主节点,化解状态分歧;也可配置人工仲裁流程,故障时快速介入。
告警与应急:配置脑裂告警(邮件、短信推送),安排运维值班,故障发生时及时人工干预,降低业务损失。
其他高可用方案
除Keepalived外,行业内还有多款成熟的高可用工具,适用于不同场景:
Heartbeat:开源经典工具,专注于节点心跳检测和资源切换,可与Pacemaker搭配实现复杂集群管理。
Pacemaker:强大的集群资源管理器,支持多种资源类型(IP、服务、存储等),调度策略灵活,适用于大规模集群。
Piranha:提供Web可视化界面,简化集群配置和管理,适合对操作便捷性有要求的中小型集群。
Keepalived核心原理
了解基础概念后,我们聚焦Keepalived——这款工具凭借轻量化、易部署的优势,成为中小企业高可用集群的首选,其核心能力基于VRRP协议实现。
Keepalived是什么
Keepalived是一款基于Linux系统的开源高可用服务软件,核心功能是实现节点故障检测和自动切换,同时支持与LVS等负载均衡工具联动,构建“高可用+负载均衡”一体化集群。它无需依赖共享存储,仅通过网络心跳即可实现主备协同,部署成本极低。
VRRP协议基础
VRRP(Virtual Router Redundancy Protocol,虚拟路由冗余协议)是Keepalived的核心依赖,其设计目标是解决静态路由的单点故障问题,通过将多个物理节点虚拟为一个“虚拟路由器”,对外提供统一访问入口。
VRRP核心组件说明:
虚拟IP(VIP):集群对外服务的统一IP地址,用户通过VIP访问服务,主备切换时VIP自动漂移,用户无感知。
主路由器(Master):优先级最高的节点,负责处理所有用户请求,同时定期向备节点发送心跳报文,告知自身状态。
备份路由器(Backup):持续监听主节点心跳,当未收到心跳(或心跳异常)时,判定主节点故障,自动升级为新主节点,接管VIP和服务。
补充:IPv4环境下,VRRP支持组播、广播、单播三种通信方式,Keepalived默认使用组播(通信地址为224.0.0.0段)传递心跳报文,配置简单且兼容性强。
Keepalived工作原理
Keepalived由三大核心模块组成,各模块协同实现高可用功能,流程清晰易懂:
核心模块(core):负责解析全局配置文件,初始化各模块,统筹整体运行流程,是Keepalived的“中枢”。
VRRP模块(vrrp):基于VRRP协议实现主备节点心跳交互、状态判断和VIP漂移,是高可用功能的核心载体。
健康检查模块(check):用于监控后端业务服务(如Nginx、Apache)的运行状态,确保仅当服务正常时,节点才参与主备竞争,避免“节点存活但服务不可用”的问题。
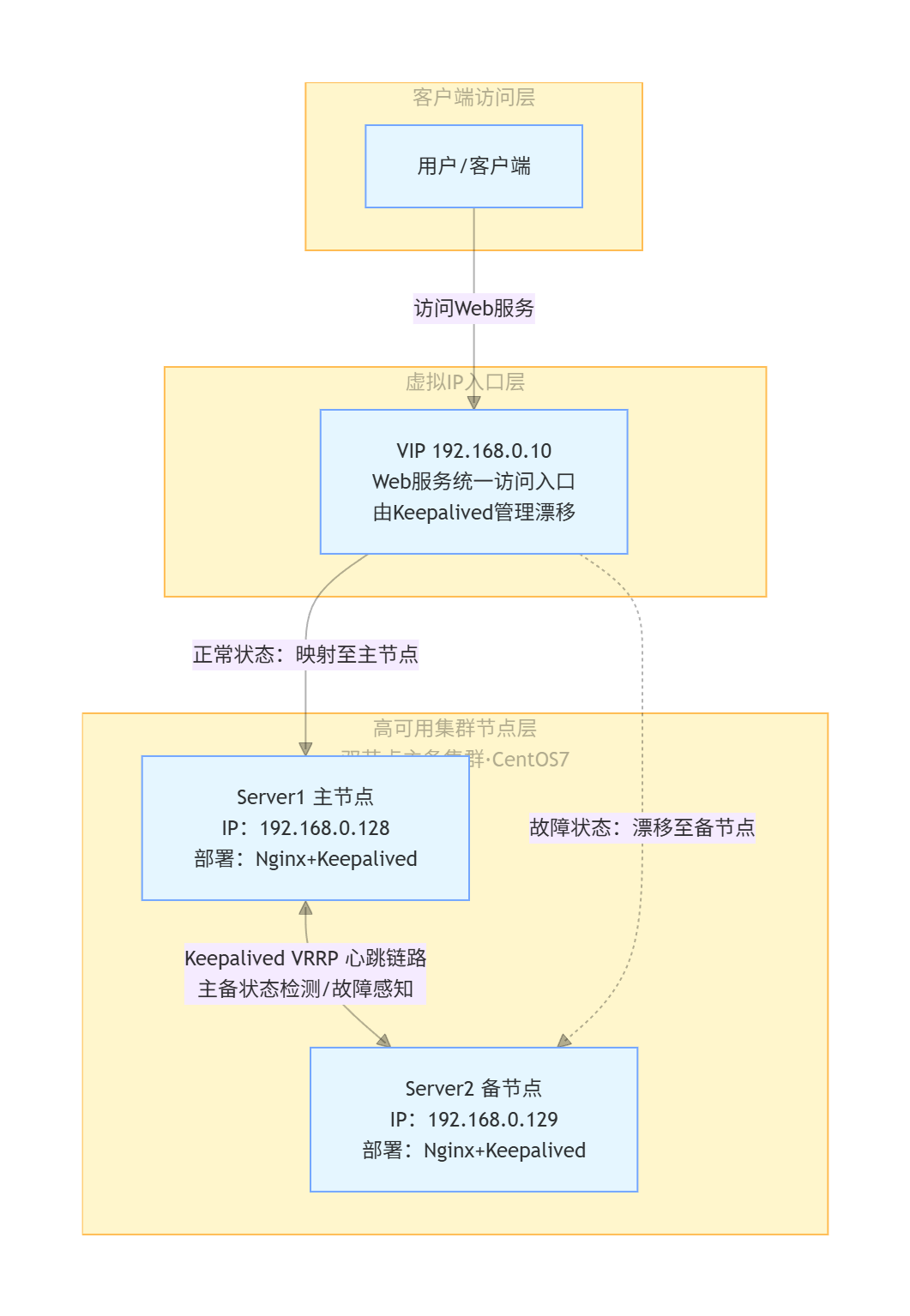
实战案例:Keepalived搭建Web高可用集群
理论结合实践,本案例将搭建“Keepalived+Nginx”主备集群,实现Web服务的高可用——当主节点Nginx故障或节点宕机时,备节点自动接管服务,保障用户访问不中断。
实验环境
本次实战采用双节点主备架构,共三台虚拟机,环境信息如下(CentOS7系统为例):
Server1(主节点):IP地址 192.168.0.128,部署Nginx+Keepalived
Server2(备份节点):IP地址 192.168.0.129,部署Nginx+Keepalived
VIP(虚拟IP):192.168.0.10,,对外提供Web服务的统一入口
远程工具:Xshell
部署步骤(Server1与Server2均执行)
主备节点(Server1和2)基础环境部署步骤完全一致,先完成Nginx和Keepalived的安装与基础配置。
安装Nginx服务
# 安装Nginx(yum方式适用于CentOS/RHEL系统,自动解决依赖)
yum -y install nginx
# 设置Nginx开机自启,避免服务器重启后服务中断
systemctl enable nginx
# 启动Nginx服务,完成基础部署
systemctl start nginx
# 编辑Web主页内容(主备节点内容区分,方便后续测试切换效果)
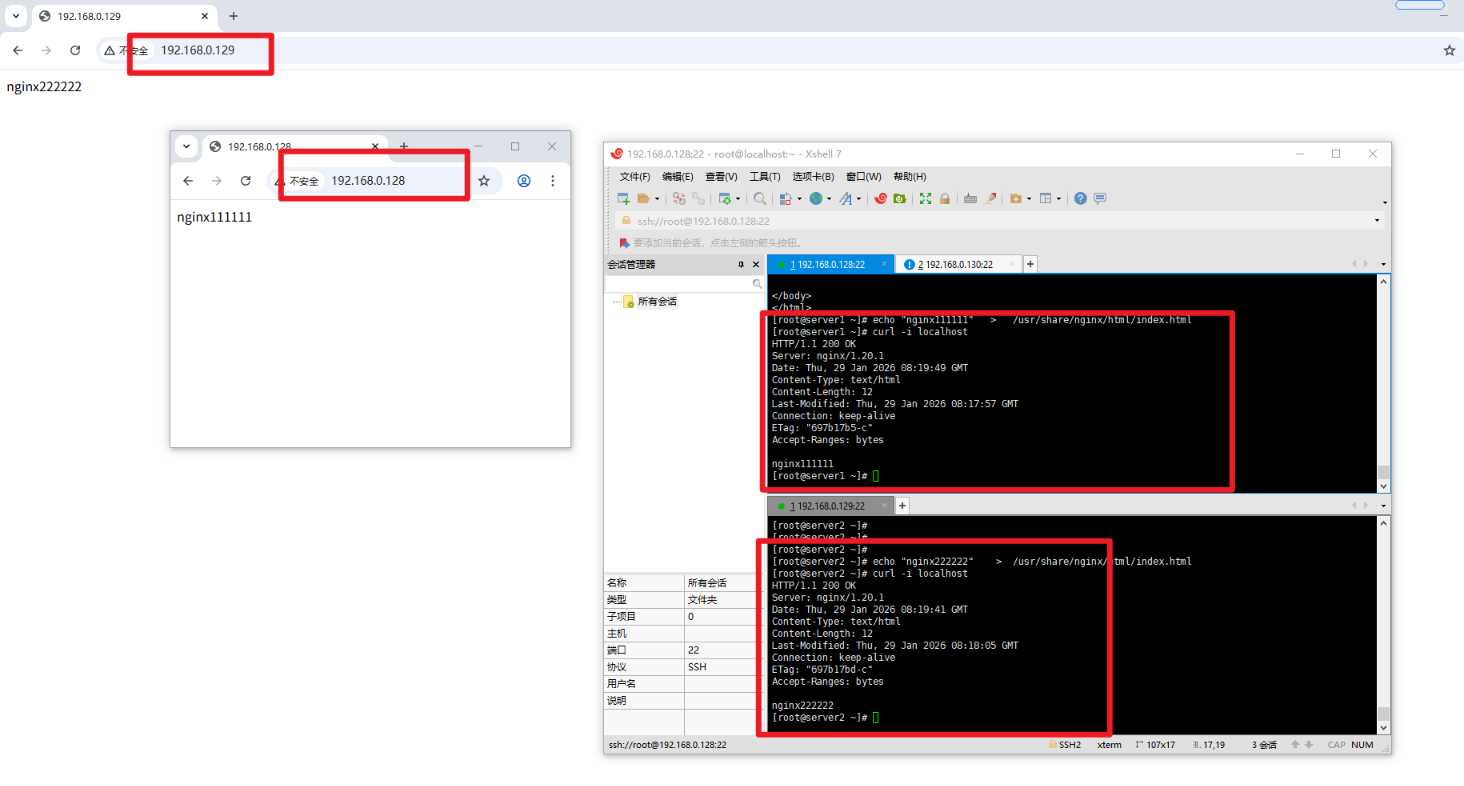
[root@server1 ~]# echo "nginx111111" > /usr/share/nginx/html/index.html
[root@server2 ~]# echo "nginx222222" > /usr/share/nginx/html/index.html
# 示例:Server1主页写“nginx111111”,Server2写“nginx222222”
# 本地访问测试,验证Nginx是否正常运行,或使用浏览器访问IP验证
curl -i localhost
安装Keepalived
# yum安装Keepalived,无需手动编译,效率更高
yum -y install keepalived
# 设置Keepalived开机自启,与Nginx保持一致的启动策略
systemctl enable keepalived.service
配置Keepalived
Keepalived核心配置文件为/etc/keepalived/keepalived.conf,主备节点需差异化配置,关键参数必须保持一致(如虚拟路由ID、认证密码)。
Server1(主节点)配置:
! Configuration File for keepalived
global_defs {
router_id 1 # 节点唯一标识,主备节点需不同(如主1、备2)
}
#vrrp_script chk_nginx { #健康检查
# script "/etc/keepalived/ck_ng.sh" #检查脚本
# interval 2 #检查频率.秒
# weight -5 #priority减5
# fall 3 #失败三次
# }
vrrp_instance VI_1 { #VI_1。实例名两台路由器相同。
state MASTER #主或者从状态
interface ens33 #心跳检测使用的IP(需根据实际环境修改,用ip a查看)
mcast_src_ip 192.168.0.128
virtual_router_id 55 #虚拟路由ID,主备节点必须一致(取值0-255)
priority 100 # 优先级,MASTER优先级需高于BACKUP(建议差值≥10)
advert_int 1 # 心跳发送间隔,单位秒(默认1秒,间隔越小切换越快)
authentication { #秘钥认证(1-8位)
auth_type PASS # 认证方式:密码认证(仅支持PASS)
auth_pass 123456 # 认证密码,主备节点必须一致(取值4-8位字符)
}
virtual_ipaddress { # 虚拟IP(VIP),可配置多个,换行分隔
192.168.0.10/24
}
# 引用Nginx监控脚本(后续添加脚本后启用,实现服务状态联动)
# track_script { #引用脚本
# chk_nginx
# }
}
Server2(备份节点)配置:
# 复制主节点配置文件到备份节点,减少重复编写(需输入主节点密码)
scp -r /etc/keepalived/keepalived.conf 192.168.0.129:/etc/keepalived/
# 编辑备份节点配置文件,修改3处关键参数(其余与主节点一致)
vi /etc/keepalived/keepalived.conf
# 修改后的配置
! Configuration File for keepalived
global_defs {
router_id 2
}
#vrrp_script chk_nginx {
# script "/etc/keepalived/ck_ng.sh"
# interval 2
# weight -5
# fall 3
# }
vrrp_instance VI_1 {
state BACKUP
interface ens33
mcast_src_ip 192.168.0.129
virtual_router_id 55
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass 123456
}
virtual_ipaddress {
192.168.0.10/24
}
# track_script {
# chk_nginx
# }
}
启动Keepalived服务
# 启动Keepalived服务,加载配置文件
systemctl start keepalived
# 可选:查看服务状态,确认启动成功(显示active(running)即为正常)
systemctl status keepalived
测试基础高可用功能
基础配置完成后,通过以下步骤验证主备切换功能是否正常:
访问VIP:在客户端浏览器输入
http://192.168.0.10,正常情况下显示主节点(Server1)的Web主页内容。模拟主节点故障:在Server1执行
systemctl stop keepalived.service停止Keepalived服务,再次访问VIP,页面自动切换为备份节点(Server2)的内容,说明故障转移生效。恢复主节点:在Server1重启Keepalived服务(
systemctl start keepalived.service),由于主节点优先级更高,VIP会自动漂移回Server1,访问VIP显示主节点内容。
解决Keepalived无法监控Nginx状态的问题
上述基础配置存在一个缺陷:Keepalived仅监控自身和网卡状态,若Nginx服务崩溃但Keepalived仍运行,会导致VIP虽在主节点,但Web服务不可用。需添加监控脚本,实现Keepalived与Nginx状态联动。
步骤1:编写Nginx监控脚本(主备节点均执行)
# 在Keepalived配置目录下创建脚本文件
vi /etc/keepalived/ck_ng.sh
# 脚本内容(逻辑:检测Nginx进程,不存在则重启;重启失败则停止Keepalived,触发切换)
#!/bin/bash
# 统计Nginx进程数量,判断服务是否运行
nginx_status=$(ps -C nginx --no-header | wc -l)
if [ $nginx_status -eq 0 ]; then
# 尝试重启Nginx服务
systemctl start nginx.service
# 等待3秒(给Nginx启动时间),再次检测进程状态
sleep 3
nginx_status=$(ps -C nginx --no-header | wc -l)
if [ $nginx_status -eq 0 ]; then
# 重启失败,说明Nginx服务异常,停止Keepalived触发故障转移
systemctl stop keepalived.service
fi
fi
# 给脚本添加执行权限(否则Keepalived无法调用)
chmod +x /etc/keepalived/ck_ng.sh
步骤2:确保Keepalived引用脚本生效
前文配置文件已添加track_script段引用脚本,此处需清除掉配置文件中的注释,重启Keepalived加载配置,使脚本生效:
# Server1和2删除主备/etc/keepalived/keepalived.conf配置文件中的脚本引用配置前面的#号
vrrp_script chk_nginx {
script "/etc/keepalived/ck_ng.sh"
interval 2
weight -5
fall 3
}
track_script {
chk_nginx
}
# 重启Keepalived服务,应用脚本配置
systemctl restart keepalived.service
步骤3:测试脚本效果
手动模拟Nginx故障,验证脚本联动效果:
- 在主节点执行
systemctl stop nginx.service停止Nginx服务,后观察Nginx服务会自动重启,并且访问192.168.0.10显示Server1的站点内容,说明脚本基础功能生效。 - 若手动禁止Nginx重启(如删除Nginx二进制文件或卸载Nginx),脚本检测到重启失败后,会停止Keepalived服务,VIP自动漂移到备节点,网页显示Server2的站点内容,实现服务容错。
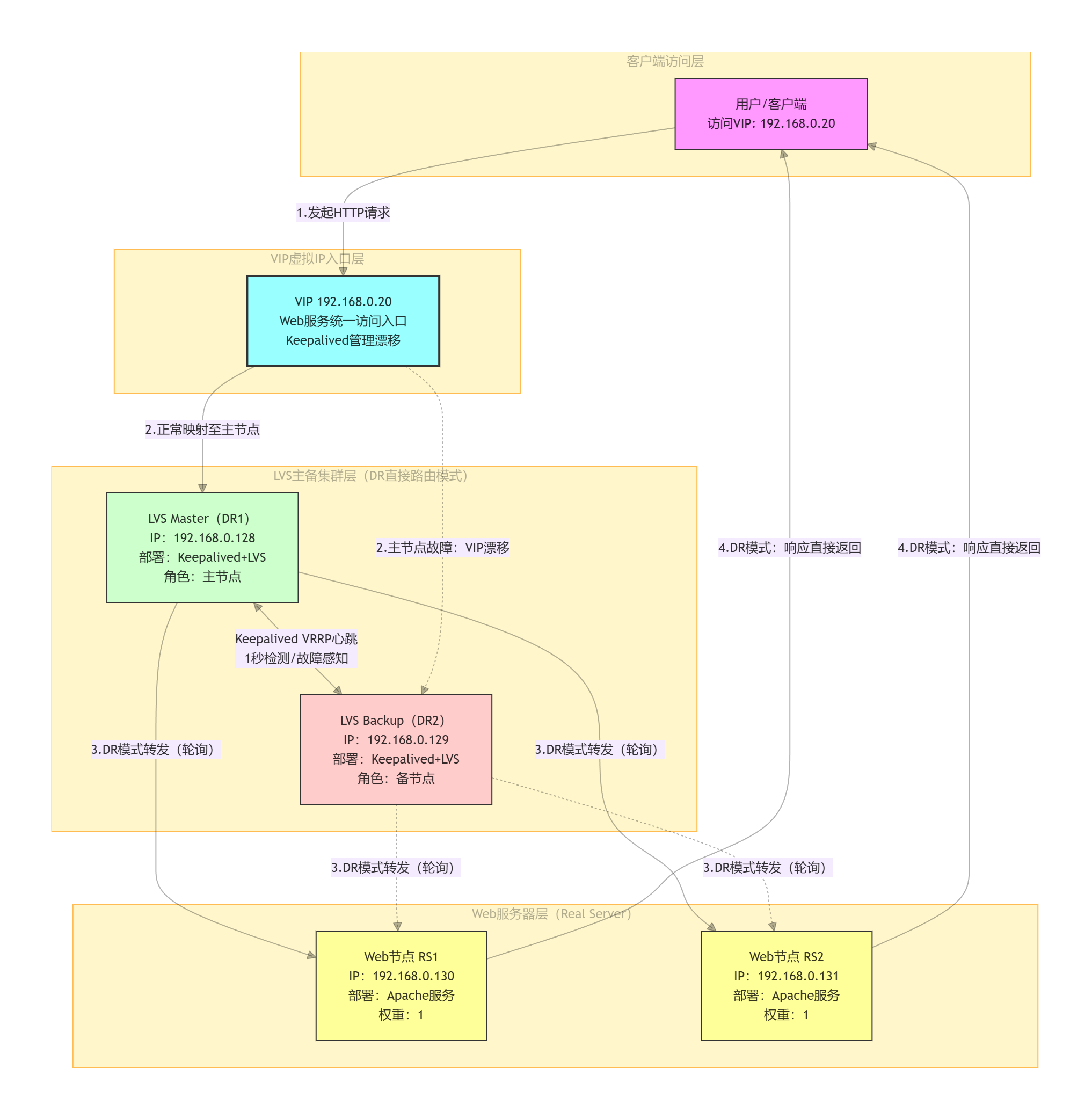
进阶实战:Keepalived+LVS高可用集群
基础案例仅解决单服务高可用,实际生产中常需同时实现“负载均衡+高可用”——通过LVS分发请求到多个Web节点,通过Keepalived保障LVS节点不中断,构建更稳定、高性能的集群架构。
环境与拓扑
本次采用“双LVS节点(主备)+双Web节点”架构,环境信息如下:
负载均衡器(Director):
Master(DR1):192.168.0.128,部署Keepalived+LVS
Backup(DR2):192.168.0.129,部署Keepalived+LVS
Web服务器(Real Server,RS):
RS1:192.168.0.130,部署Apache服务
RS2:192.168.0.131,部署Apache服务
VIP:192.168.0.20,对外统一访问入口
LVS模式:DR(直接路由)模式,转发效率最高,适用于Web服务场景
部署步骤
负载均衡器配置(Master与Backup)
负载均衡器需安装Keepalived(高可用)和IPVSADM(LVS管理工具),通过Keepalived配置LVS规则,实现规则自动同步。
在Master和Backup上安装配置Keepalived
yum install keepalived ipvsadm -y #ipvsadm安装并不启动Master节点配置Keepalived(整合LVS规则):
vim /etc/keepalived/keepalived.conf
# 配置文件内容如下
! Configuration File for keepalived
# 全局配置块:定义Keepalived的全局参数
global_defs {
router_id Director1 # 本节点的唯一标识(主备节点需设置不同名称,备节点可设为Director2)
}
# VRRP实例配置块:核心的高可用心跳与VIP管理配置
vrrp_instance VI_1 {
state MASTER # 节点角色(主节点设为MASTER,备节点需改为BACKUP)
interface ens33 # 用于发送VRRP心跳包的网卡(需与服务器实际网卡名一致)
virtual_router_id 51 # 虚拟路由ID(主备节点必须保持一致,取值范围0-255)
priority 150 # 节点优先级(数值越高优先级越高,备节点需设更小值如100)
advert_int 1 # VRRP心跳包发送间隔(单位:秒,主备节点需一致)
# 认证配置块:防止非法节点加入集群
authentication {
auth_type PASS # 认证类型(PASS为密码认证,主备需一致)
auth_pass 1111 # 认证密码(主备节点必须完全一致)
}
# 虚拟IP(VIP)配置块:定义漂移的VIP地址
virtual_ipaddress {
192.168.0.20/24 dev ens33 # 配置VIP地址/子网掩码 + 绑定的网卡(主备节点配置需完全一致)
}
}
# LVS虚拟服务配置块:定义LVS负载均衡规则(Keepalived集成LVS功能)
virtual_server 192.168.0.20 80 { # 绑定VIP和监听端口(对应上面配置的VIP + 业务端口80)
delay_loop 3 # 健康检查轮询间隔(每隔3秒检查后端real_server的状态)
lb_algo rr # LVS调度算法(rr=轮询,其他可选wrr/ip_hash等)
lb_kind DR # LVS集群模式(DR=直接路由模式,性能最优的LVS模式)
protocol TCP # 协议类型(业务为HTTP/HTTPS时用TCP)
# 后端真实服务器1配置
real_server 192.168.0.130 80 {
weight 1 # 权重(数值越高被调度的概率越大,相同权重则轮询)
# TCP健康检查配置:检测后端服务是否存活
TCP_CHECK {
connect_timeout 3 # 连接超时时间(3秒内连不上则判定该节点故障)
}
}
# 后端真实服务器2配置
real_server 192.168.0.131 80 {
weight 1 # 权重(与上一节点一致则轮询调度)
# TCP健康检查配置
TCP_CHECK {
connect_timeout 3 # 连接超时时间(与上一节点保持一致)
}
}
}Backup节点配置Keepalived:
# 复制Master节点配置文件到Backup节点
scp /etc/keepalived/keepalived.conf 192.168.0.129:/etc/keepalived/
# 拷贝后,修改Backup的keepalived.conf配置文件
router_id Director2
state BACKUP
priority 100
# 配置示例
! Configuration File for keepalived
global_defs {
router_id Director2
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.20/24 dev ens33
}
}
virtual_server 192.168.0.20 80 {
delay_loop 3
lb_algo rr
lb_kind DR
protocol TCP
real_server 192.168.0.130 80 {
weight 1
TCP_CHECK {
connect_timeout 3
}
}
real_server 192.168.0.131 80 {
weight 1
TCP_CHECK {
connect_timeout 3
}
}
}
master和backup上启动服务
# 设置开机自启
systemctl enable keepalived
# 启动服务
systemctl start keepalived
# 重启系统(可选,建议执行)
reboot
Web服务器配置(RS1与RS2均执行)
LVS-DR模式要求后端Web节点配置VIP(绑定到回环网卡),并抑制ARP广播,避免地址冲突,同时部署Apache服务提供Web内容。
安装并启动Apache服务:
yum install -y httpd
systemctl start httpd
systemctl enable httpd
# 配置不同的web界面
[root@rs1 ~]# echo "web1111" > /var/www/html/index.html
[root@rs2 ~]# echo "web2222" > /var/www/html/index.html配置虚拟地址
cp /etc/sysconfig/network-scripts/{ifcfg-lo,ifcfg-lo:0}
vim /etc/sysconfig/network-scripts/ifcfg-lo:0
# 写入以下内容,其他行注释掉或删掉
DEVICE=lo:0
IPADDR=192.168.0.20
NETMASK=255.255.255.255
ONBOOT=yes配置路由
在两台机器(RS)上,添加一个路由:route add -host 192.168.0.20 dev lo:0
确保如果请求的目标IP是$VIP,那么让出去的数据包的源地址也显示为$VIPvim /etc/rc.local
# 写入以下内容
/sbin/route add -host 192.168.0.20 dev lo:0配置ARP
忽略arp请求,可以回复
vim /etc/sysctl.conf
# 写入以下内容
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
net.ipv4.conf.default.arp_ignore = 1
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_ignore = 1
net.ipv4.conf.lo.arp_announce = 2重启系统确保所有配生效且持久化
reboot
集群测试
集群部署完成后,从负载均衡、高可用、故障容错三个维度进行测试,验证整体功能。
验证LVS规则:在Master节点执行 ipvsadm -L,可查看LVS转发规则,显示后端两个Web节点(RS1、RS2)状态为“ACTIVE”,说明规则生效。

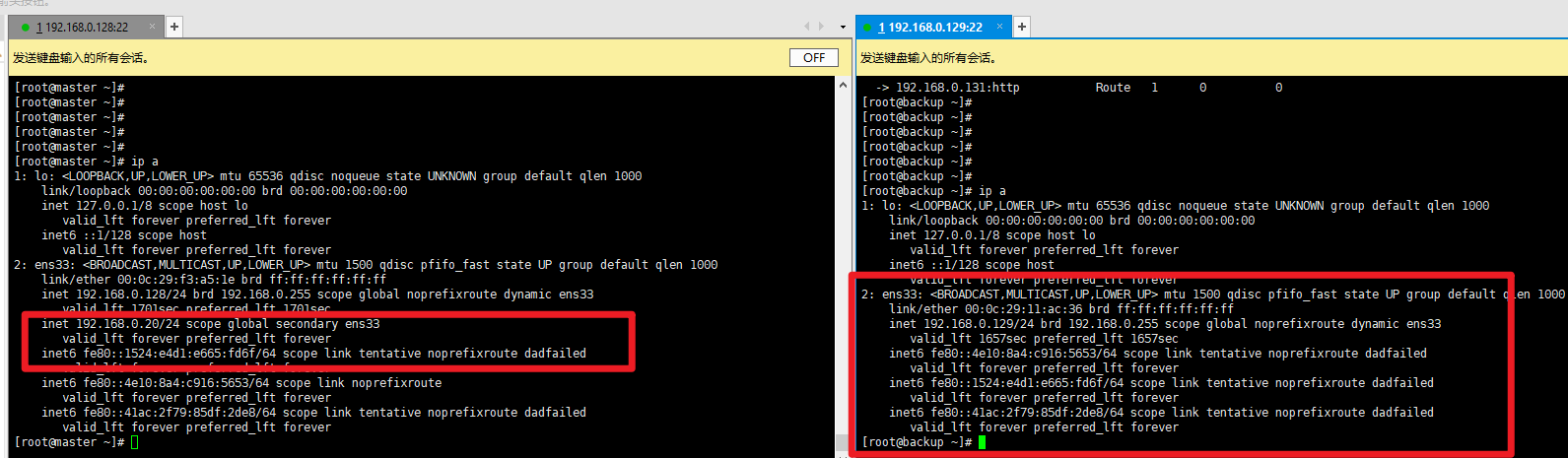
验证VIP位置:在Master节点执行ip a,可看到VIP(192.168.0.20)绑定在ens33网卡上;备节点无VIP,符合主备逻辑。
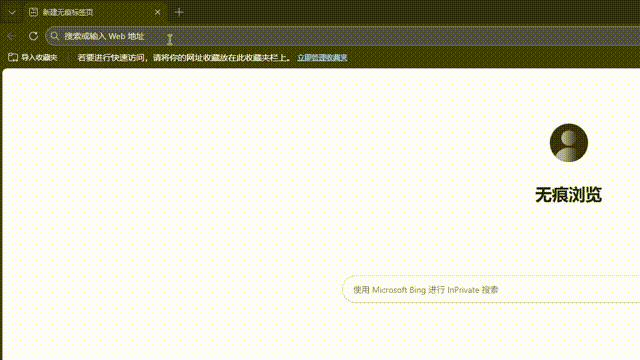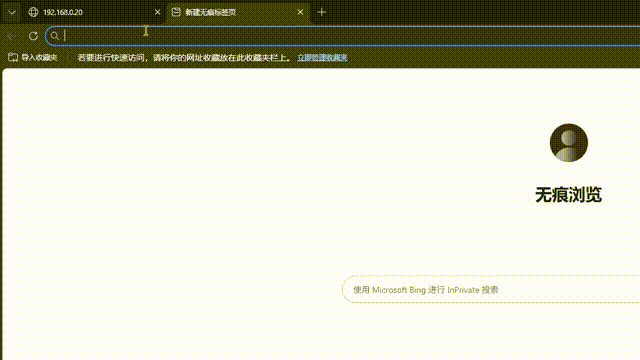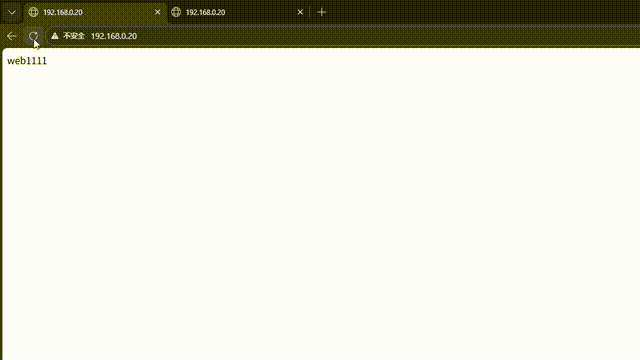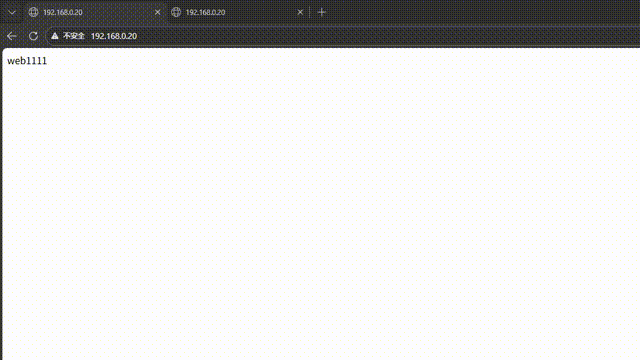
负载均衡测试:客户端浏览器访问 http://192.168.0.20,多次刷新页面,可看到内容在RS1和RS2之间切换,验证轮询算法生效。
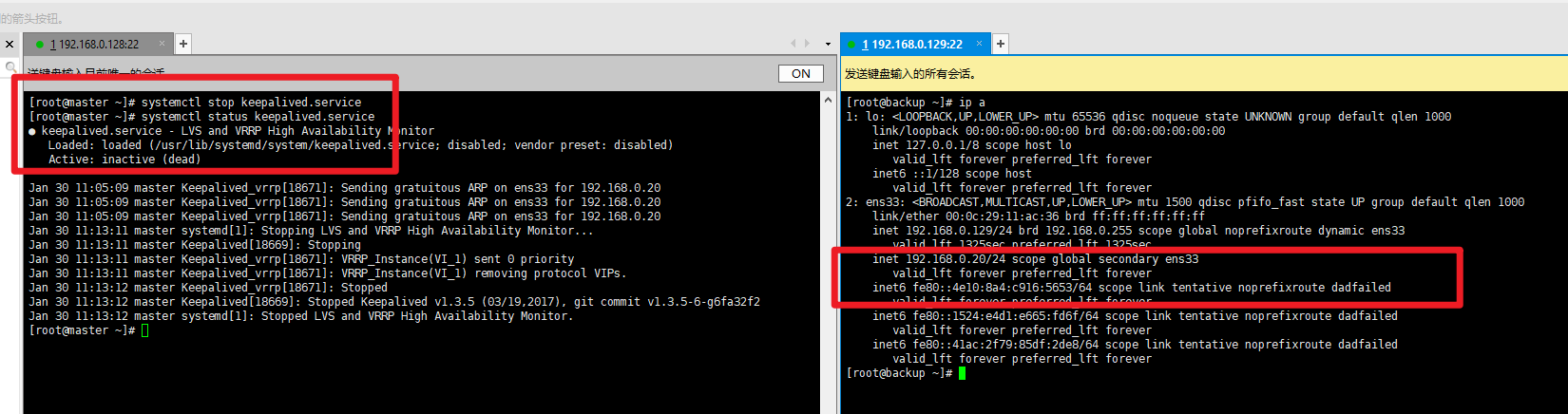
高可用测试:在Master节点执行systemctl stop keepalived.service 停止服务,执行ip a 可看到VIP漂移到Backup节点;客户端访问VIP仍正常,说明高可用生效。
后端节点故障测试:在RS1节点执行 systemctl stop httpd.service 停止Apache服务,访问VIP时,请求自动转发到RS2;重启RS1的Apache后,请求再次均匀分发,验证后端容错功能。
