在数据库运维体系中,备份是保障数据安全的核心环节,也是业务连续性的重要支撑。无论是应对硬件故障、自然灾害等不可抗力因素,还是处理人为误操作等意外情况,完善的备份策略都能确保数据在灾难发生时快速恢复,将损失降至最低。
备份的核心概念
备份的必要性
- 数据安全保障:防范硬件故障、自然灾害、网络攻击等导致的数据丢失
- 业务连续性:确保在数据损坏时能够快速恢复,减少业务中断时间
- 合规要求:满足行业监管对数据保留和恢复能力的要求
- 测试与开发支持:为测试环境和开发环境提供数据副本
备份的核心目标
- 数据一致性:确保备份数据与源数据完全一致,无 corruption
- 服务可用性:最小化备份过程对生产环境的影响,避免服务中断
- 恢复效率:确保在需要时能够快速、完整地恢复数据
备份技术分类
物理备份(冷备份)
- 直接复制数据库文件,适用于大型数据库环境
- 不受存储引擎限制,但通常需要停止服务
- 常用工具:tar、cp、scp等
- 优势:备份速度快,恢复时间短;劣势:需要停机,停止服务,不能跨版本恢复
逻辑备份(热备份)
- 备份为建表、插入等执行的SQL语句(DDL DML DCL),适用于中小型数据库
- 可在服务运行状态下执行
- 常用工具:mysqldump、mydumper等
- 优势:灵活性高,可跨版本恢复;劣势:备份速度较慢,占用资源较多
备份策略类型
完全备份:备份整个数据库的所有内容
优势:恢复简单直接;劣势:备份时间长,占用空间大
通俗的说就是直接把数据库全部打包备份,等哪一天出问题了,可以直接用一个备份恢复所有的数据。
就像你给整个文件夹做了一个完整的压缩包,周一上班的时候,把数据库里所有的表、所有的数据,完完整整全部备份一遍,生成一个独立完整的备份包。
不管之前有没有备份过,每次全量备份都会把当前数据库里的所有内容全部复制备份,不挑内容、不做筛选。
恢复的时候最简单:如果要恢复到周一的状态,只用这一个周一的全量备份包,就能直接把数据库恢复完整,不需要其他任何文件。
增量备份:仅备份自上一次备份以来发生变化的数据
优势:备份速度快,占用空间小;劣势:恢复时需要按顺序应用所有增量备份,恢复时间长
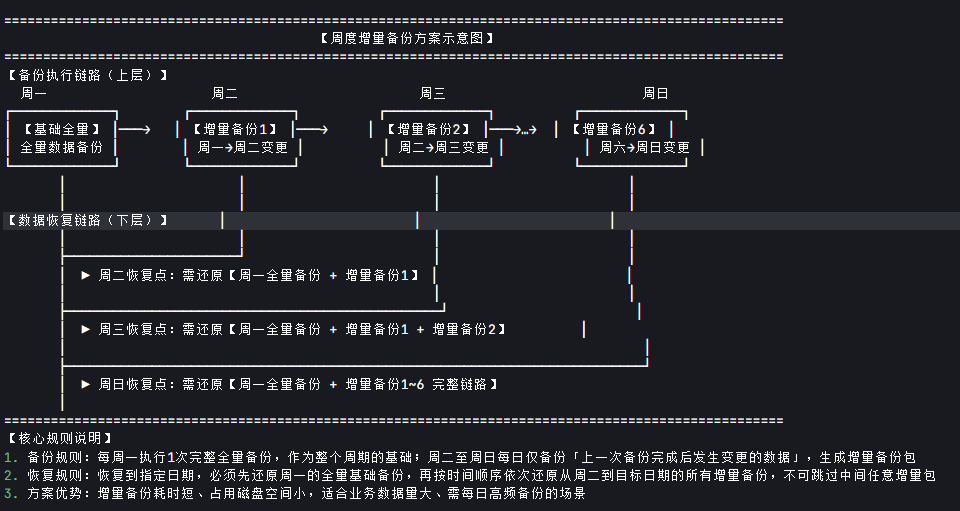
这幅图通俗的讲就是给数据库在周一做一次完整备份后,每天在上一天的基础上备份变化的数据。例如周一做完完整备份后,周二增删了一些数据,那么周二备份的只有增删的这些数据。同理,周三备份的是周二的基础上变化的数据,假设如今周五我们的数据库出现了问题需要恢复到周四,那么我们就要按顺序用周一的完全备份+周二(增量)+周三(增量)+周四(增量)实现恢复数据。
再详细一些描述备份过程,我们周一先做一次完整的全量备份,作为整个周期的基础。
周二下班备份时,只备份【周一全量备份完成后,到周二下班,这段时间里新增、修改、删除的变化数据】,没动过的数据一概不备份,备份包很小,速度很快。
周三下班备份时,只备份【周二增量备份完成后,到周三下班,这段时间里新变化的数据】,只和上一次的增量备份比,不用回头看周一的全量备份。
周四、周五的备份,都是同一个逻辑:永远只备份和上一次备份相比,新变化的那一点点数据。
恢复的时候:如果周五数据库坏了,要恢复到周四下班的状态,必须按顺序操作:先还原周一的完整全量备份,再依次叠加周二的增量包、周三的增量包、周四的增量包,四个包一个都不能少,顺序也不能乱,少一个或者顺序错了,数据就恢复不完整。
差异备份:备份自上一次完全备份以来发生变化的数据
优势:恢复时只需应用完全备份和最新差异备份;劣势:备份文件随时间增长
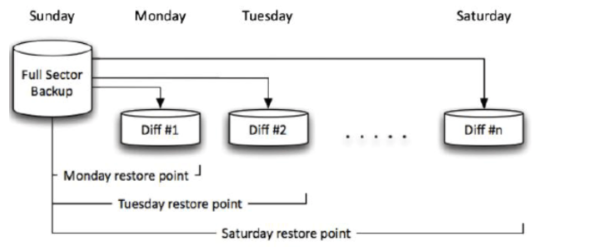
我们还是周一先做一次完整的全量备份,作为整个周期唯一的固定基准。
周二下班备份时,只备份【周一全量备份完成后,到周二下班,所有变化的数据】,这一步和增量备份完全一样。
周三下班备份时,就和增量备份有本质区别了:它会备份【周一全量备份完成后,到周三下班,所有变化的全部数据】,不管周二有没有备份过,都只以周一的全量为基准,把到当前为止所有的变化都备份下来)。
周四、周五的备份,都是同一个逻辑:永远以周一的全量备份为唯一基准,每次都备份从周一全量之后,到当前时间点的所有累计变化数据。
恢复的时候:如果周五数据库坏了,要恢复到周四下班的状态,只用两个包就够了:先还原周一的完整全量备份,再直接叠加周四的差异备份包,不用周二、周三的备份包,就能直接恢复到周四的状态,步骤少,也不依赖中间的备份文件。
实战案例1:使用Percona XtraBackup进行热备份
工具简介
工具Logo:
Percona XtraBackup是一款开源免费的MySQL热备份工具,由Percona公司开发维护,专为InnoDB和XtraDB存储引擎优化,具有以下核心优势:
- 非阻塞备份:在备份过程中不阻塞数据库的读写操作
- 热备份能力:无需停止MySQL服务即可完成备份
- 增量备份支持:可基于上一次备份进行增量备份,节省空间和时间
- 跨服务器迁移:支持在线表迁移和复制环境搭建
- 低资源占用:备份过程对服务器性能影响小
安装步骤
配置YUM仓库
安装数据库:MySQL Linux版的安装与配置 – Breeze
安装依赖包:
yum install -y yum-utils
yum install mysql-community-libs-compat -y #如出现秘钥校验不匹配下载失败加上 --nogpgcheck 选项跳过秘钥验证安装Percona仓库:
yum -y install https://downloads.percona.com/downloads/Percona-XtraBackup-2.4/Percona-XtraBackup-2.4.5/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.5-1.el7.x86_64.rpm
安装Percona XtraBackup
方式一:wget https://downloads.percona.com/downloads/Percona-XtraBackup-2.4/Percona-XtraBackup-2.4.5/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.5-1.el7.x86_64.rpm
yum -y install percona-xtrabackup-24-2.4.5-1.el7.x86_64.rpm方式二:
下载我提供的rpm软件资源包,上传后安装
通过网盘分享的文件:percona-xtrabackup-24-2.4.5-1.el7.x86_64.rpm
链接: https://pan.baidu.com/s/1xqvDRO7Q6G248xcj383s_Q 提取码: 7878yum -y install percona-xtrabackup-24-2.4.5-1.el7.x86_64.rpm方式三:
下载我提供的软件压缩包,上传后解压,下载所有解压出的rpm包通过网盘分享的文件:percona-xtrabackup24.rpm.zip
链接: https://pan.baidu.com/s/1tTDSD3PLZQ7XgTFB3loobg 提取码: 7878unzip percona-xtrabackup24.rpm.zip
cd percona-xtrabackup
yum localinstall -y *.rpm验证安装结果
rpm -ql percona-xtrabackup-24准备测试数据
mysql> create database company;
mysql> CREATE TABLE company.employee5(
id int primary key AUTO_INCREMENT not null, -- 主键,自增,非空(员工编号)
name varchar(30) not null, -- 员工姓名,非空
sex enum('male','female') default 'male' not null, -- 性别,枚举类型,默认男性,非空
hire_date date not null, -- 入职日期,非空
post varchar(50) not null, -- 岗位,非空
job_description varchar(100), -- 岗位职责,可空
salary double(15,2) not null, -- 薪资,双精度浮点型,非空(保留2位小数)
office int, -- 办公室编号,可空
dep_id int -- 部门编号,可空
);
mysql> insert into company.employee5(name,sex,hire_date,post,job_description,salary,office,dep_id) values
('jack','male','20180202','instructor','teach',5000,501,100),
('tom','male','20180203','instructor','teach',5500,501,100),
('robin','male','20180202','instructor','teach',8000,501,100),
('alice','female','20180202','instructor','teach',7200,501,100),
('aofa','male','20180202','hr','hrcc',600,502,101),
('harry','male','20180202','hr',NULL,6000,502,101),
('emma','female','20180206','sale','salecc',20000,503,102),
('christine','female','20180205','sale','salecc',2200,503,102),
('zhuzhu','male','20180205','sale',NULL,2200,503,102),
('gougou','male','20180205','sale','',2200,503,102);
mysql> select * from employee5;
+----+-----------+--------+------------+------------+-----------------+----------+--------+--------+
| id | name | sex | hire_date | post | job_description | salary | office | dep_id |
+----+-----------+--------+------------+------------+-----------------+----------+--------+--------+
| 1 | jack | male | 2018-02-02 | instructor | teach | 5000.00 | 501 | 100 |
| 2 | tom | male | 2018-02-03 | instructor | teach | 5500.00 | 501 | 100 |
| 3 | robin | male | 2018-02-02 | instructor | teach | 8000.00 | 501 | 100 |
| 4 | alice | female | 2018-02-02 | instructor | teach | 7200.00 | 501 | 100 |
| 5 | aofa | male | 2018-02-02 | hr | hrcc | 600.00 | 502 | 101 |
| 6 | harry | male | 2018-02-02 | hr | NULL | 6000.00 | 502 | 101 |
| 7 | emma | female | 2018-02-06 | sale | salecc | 20000.00 | 503 | 102 |
| 8 | christine | female | 2018-02-05 | sale | salecc | 2200.00 | 503 | 102 |
| 9 | zhuzhu | male | 2018-02-05 | sale | NULL | 2200.00 | 503 | 102 |
| 10 | gougou | male | 2018-02-05 | sale | | 2200.00 | 503 | 102 |
+----+-----------+--------+------------+------------+-----------------+----------+--------+--------+
10 rows in set (0.00 sec)
完全备份实战
# 创建备份目录
mkdir -p /xtrabackup/full
# 执行完全备份
innobackupex --user=root --password='Abc@666666' /xtrabackup/full
# 查看备份目录结构(会自动生成以日期为名的备份文件)
ls -la /xtrabackup/full/
# 查看备份生成的二进制日志位置信息(了解)
cat /xtrabackup/full/$(ls -t /xtrabackup/full/ | head -1)/xtrabackup_binlog_info
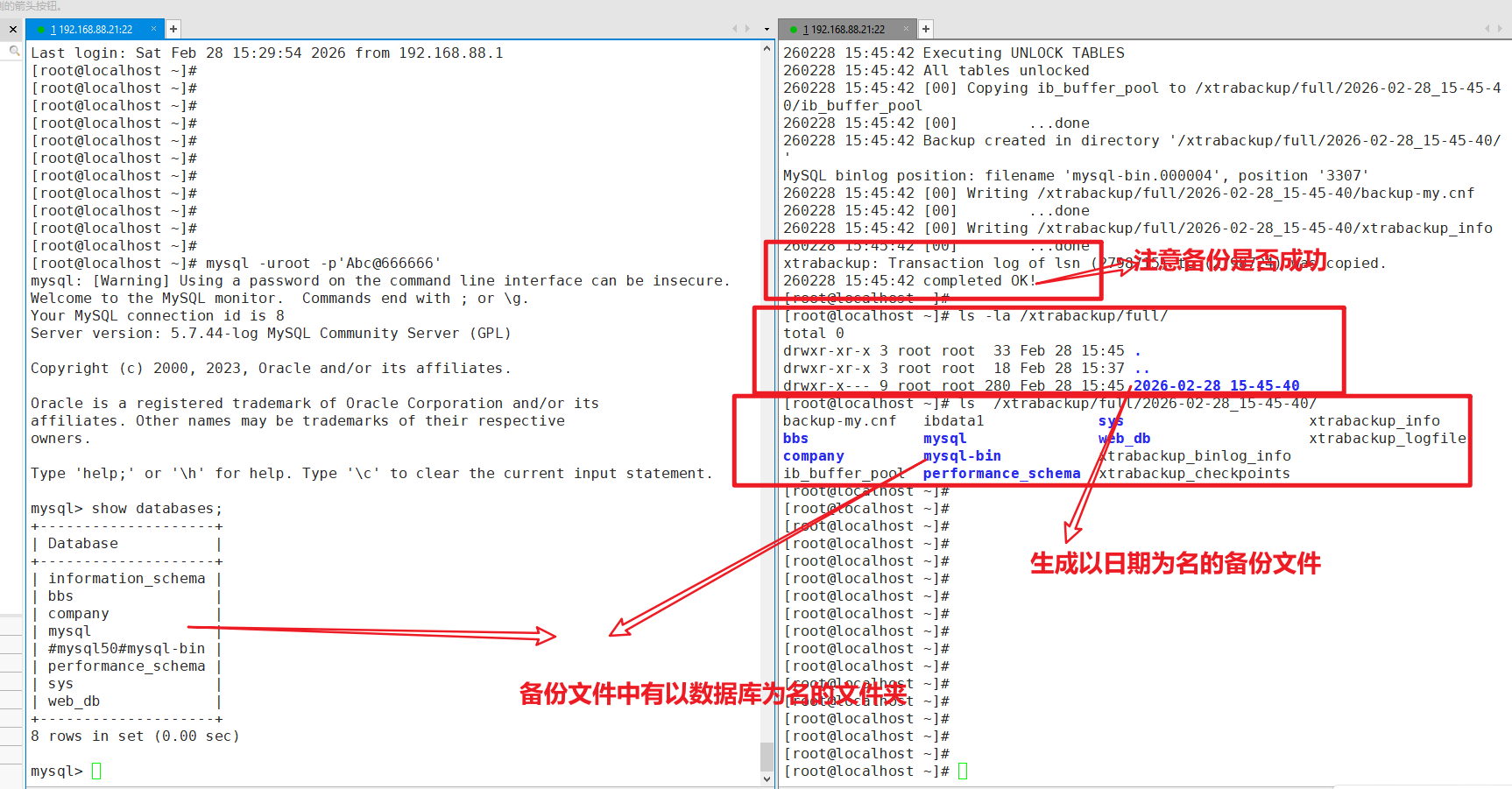
至此,你的数据库就全部备份了下来,下面环境模拟数据库遭到破坏,需要使用备份来恢复数据
# 停止MySQL服务
systemctl stop mysqld
# 清理数据目录(模拟数据损坏)
rm -rf /var/lib/mysql/*
rm -rf /var/log/mysqld.log
此时就算启动也无法登录数据库服务
完全恢复实战
# 确保停止MySQL服务且清空数据目录(如重启过数据库就在清理一遍,确保数据库是干净的,否则会恢复失败)
systemctl stop mysqld
rm -rf /var/lib/mysql/*
rm -rf /var/log/mysqld.log
# 准备备份(生成回滚日志来指定备份点,确保数据一致性)
innobackupex --apply-log /xtrabackup/full/2026-02-28_15-45-40/
# 恢复备份文件
innobackupex --copy-back /xtrabackup/full/$(ls -t /xtrabackup/full/ | head -1)/
# 修复文件权限
chown -R mysql:mysql /var/lib/mysql
# 启动MySQL服务
systemctl start mysqld
# 验证恢复结果
[root@localhost ~]# mysql -uroot -p'Abc@666666' -e "SHOW DATABASES;"
mysql: [Warning] Using a password on the command line interface can be insecure.
+--------------------+
| Database |
+--------------------+
| information_schema |
| bbs |
| company |
| mysql |
| #mysql50#mysql-bin |
| performance_schema |
| sys |
| web_db |
+--------------------+
–apply-log 的核心作用:让备份文件「一致化」
innobackupex --apply-log 会模拟 MySQL 启动时的「崩溃恢复流程」,对备份文件做两件关键事:
重做(redo):把 redo log 里的已提交事务,应用到数据文件中(补全已提交但未刷盘的数据);
回滚(undo):把 undo log 里的未提交事务,从数据文件中回滚(清理未完成的脏数据)。
执行完后,备份目录里的文件就变成了「备份时刻的一致性数据」—— 相当于 “备份时刻数据库瞬间停服,拿到的干净备份”。
–copy-back 的作用:把一致化的文件恢复到数据库目录
只有经过 --apply-log 处理后的 “干净文件”,复制到 MySQL 的数据目录(/var/lib/mysql)后,数据库启动时才会识别到「完整、一致的数据」,正常启动且数据无丢失、无混乱。
来一个通俗一点的例子 把 MySQL 想象成你家包饺子的厨房,你要备份「包好的饺子」(对应数据库里的有效数据):
备份(innobackupex 直接备份) 你趁家人还在厨房包饺子(数据库不停服、还在读写数据),直接把案板上的饺子全装到盒子里(备份)。
这时候盒子里的饺子有两种:
- 已经包好、捏紧皮的(对应「已提交的有效数据」,比如用户刚提交的订单);
- 只包了一半、皮还没捏紧的(对应「没提交的无效数据」,比如用户刚点下单但还没付款的临时数据);甚至还有掉出来的饺子馅(对应「临时缓存数据」)。这个盒子里的饺子是「乱的、没法直接吃的」—— 这就是你备份目录里的原始数据。
–apply-log(整理备份 = 把乱饺子整理成能吃的) 你把装饺子的盒子拿到客厅,做两件事:
① 把没包完的半成品饺子拆了、馅倒掉(对应「回滚未提交的无效数据」);
② 把捏松的饺子皮捏紧、缺馅的补满(对应「补全已提交但没存好的有效数据」);
最后盒子里只剩「完整、能直接煮的饺子」—— 这就是「一致性备份数据」。这一步就是 –apply-log 的核心:把备份里的「乱数据」整理成「干净可用的完整数据」。
–copy-back(恢复备份 = 把整理好的饺子放回厨房) 你把整理好的完整饺子,端回厨房的盘子里(对应把干净数据复制到 MySQL 的数据目录)。这时家人回来,直接煮饺子就能吃(对应数据库启动后,能正常用、数据不丢、不混乱)。
如果跳过 –apply-log,直接用 –copy-back 把「半成品 + 成品」的乱饺子放回厨房:厨房(数据库)一看全是烂饺子、散馅,根本没法煮(启动失败);就算勉强煮了,吃的时候不是漏馅就是没熟(数据混乱、丢数据,甚至数据库崩溃)。 一句话总结: –apply-log = 把备份的「乱数据」理干净;–copy-back = 把干净的数据放回数据库;
增量备份实战
测试数据还是用company那个数据库
执行基础完全备份(周一)
# 清理旧备份
rm -rf /xtrabackup/*
# 修改日期(模拟周一)
[root@localhost ~]# date
Mon Mar 2 10:00:02 CST 2026
# 执行完全备份
innobackupex --user=root --password='Abc@666666' /xtrabackup
# 查看周一备份目录
[root@localhost ~]# ls /xtrabackup/
2026-03-02_10-00-41执行第一次增量备份(周二)
# 插入新数据(模拟在周二备份前数据产生的变化)
INSERT INTO employee5 (
id, name, sex, hire_date, post, job_description, salary, office, dep_id
) VALUES (
11, 'zhangxiaoxiao', 'female', CURDATE(), 'instructor', 'teach advanced', 8500.00, 501, 100
);
# 修改日期(模拟周二)
[root@localhost ~]# date -s "2026-03-03 10:00:00"
Tue Mar 3 10:00:00 CST 2026
# 执行增量备份,基于周一的完全备份
innobackupex --user=root --password='Abc@666666' --incremental /xtrabackup/ --incremental-basedir=/xtrabackup/2026-03-02_10-00-41
# 查看周二备份目录
[root@localhost ~]# ls /xtrabackup/
2026-03-03_10-03-26执行第二次增量备份(周三)
# 插入新数据
INSERT INTO employee5 (
id, name, sex, hire_date, post, job_description, salary, office, dep_id
) VALUES (
12, 'zhaodezhu', 'male', CURDATE(), 'hr', 'recruitment', 7500.00, 502, 101
);
# 删除数据
DELETE FROM employee5 WHERE name = 'alice';
#修改日期(模拟周三)
[root@localhost ~]# date -s "2026-03-04 10:00:00"
Wed Mar 4 10:00:00 CST 2026
# 执行增量备份,基于周二的增量备份
innobackupex --user=root --password='Abc@666666' --incremental /xtrabackup/ --incremental-basedir=/xtrabackup/2026-03-03_10-03-26
# 查看周三备份目录
[root@localhost ~]# ls /xtrabackup/
2026-03-02_10-00-41 2026-03-03_10-03-26 2026-03-04_10-02-00
增量恢复实战
# 停止MySQL服务
systemctl stop mysqld
# 清理数据目录(模拟数据库损坏)
rm -rf /var/lib/mysql/*
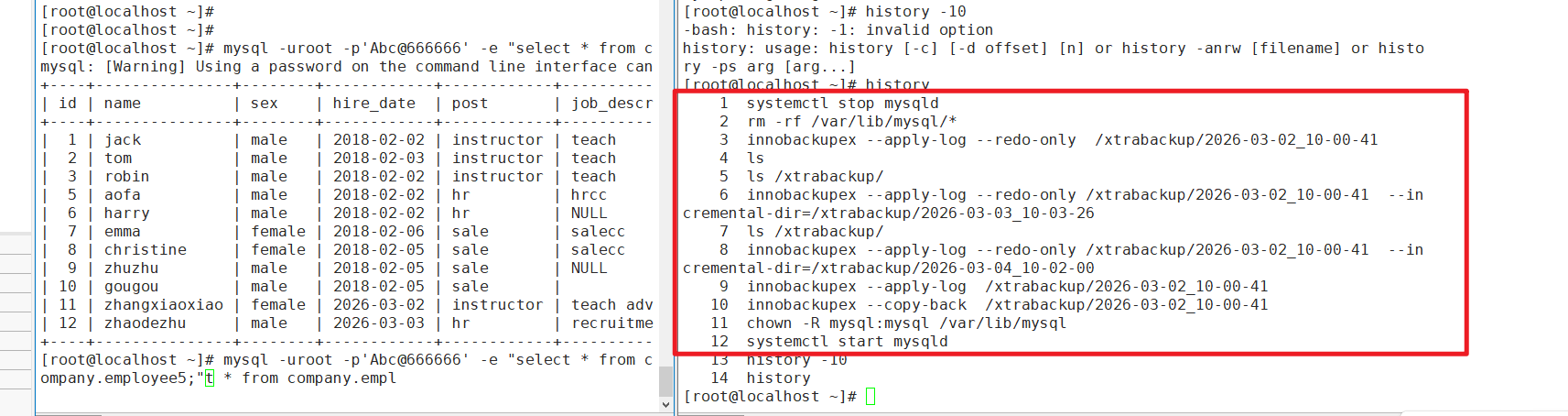
# 准备完全备份(使用--redo-only避免回滚未提交事务)
innobackupex --apply-log --redo-only /xtrabackup/2026-03-02_10-00-41
# 应用周二增量备份
innobackupex --apply-log --redo-only /xtrabackup/2026-03-02_10-00-41 --incremental-dir=/xtrabackup/2026-03-03_10-03-26
# 应用周三增量备份
innobackupex --apply-log --redo-only /xtrabackup/2026-03-02_10-00-41 --incremental-dir=/xtrabackup/2026-03-04_10-02-00
# 最终准备备份(回滚未提交事务)
innobackupex --apply-log /xtrabackup/2026-03-02_10-00-41
# 恢复备份文件
innobackupex --copy-back /xtrabackup/2026-03-02_10-00-41
# 修复文件权限
chown -R mysql:mysql /var/lib/mysql
# 启动MySQL服务
systemctl start mysqld
# 验证恢复结果(可以看到我们数据都回来了)
mysql -uroot -p'Abc@666666' -e "select * from company.employee5;"
本次操作完成了周一到周三共三天数据的恢复,整体逻辑如下:
首先对周一的数据做了全量备份(这是整个恢复的基准);
周二、周三的备份均为「增量备份」—— 仅备份前一天数据的变化部分(周二基于周一、周三基于周二);
恢复时需按顺序处理备份文件:
- 先对周一的全量备份执行
--redo-only预处理(只重做已提交事务,不回滚未提交事务); - 再以周一备份为基础,执行
--redo-only叠加周二的增量备份(此时周二的增量数据已整合到周一备份中); - 接着继续执行
--redo-only叠加周三的增量备份; - 最后对整合了周一、周二、周三数据的备份文件执行
--apply-log完整预处理(回滚所有未提交事务);
- 先对周一的全量备份执行
完成上述 “准备备份” 的预处理后,再执行恢复命令,将整理好的一致性数据拷贝回数据库目录,最终完成全量 + 增量的完整恢复。
再用一个通俗的例子讲:
- 周一的全量备份:你包了一盒饺子(有成品、有半成品),先执行
--redo-only(只补成品,不扔半成品); - 叠加周二增量:把周二新包好的饺子放进周一的盒子里(还是
--redo-only,只补不扔); - 叠加周三增量:把周三新包好的饺子也放进去(依然
--redo-only); - 最终整理:对装了周一 + 周二 + 周三所有成品饺子的盒子,执行
--apply-log(补全捏松的饺子 + 扔掉所有半成品); - 恢复备份:把这盒 “干净、完整的饺子” 端回厨房(拷贝回数据库),就能正常煮了。
核心总结
--redo-only= 往饺子盒里 “只加新包好的饺子,不扔没包完的”,专为叠加增量准备;--apply-log= 把饺子盒整理干净(补好的留下、没包完的扔掉),整理完才能端去煮(恢复)。
如果只想恢复到周二的数据应该怎么操作? 上面的操作中我们不回滚周三的备份就行,也就是跳过(# 应用周三增量备份)这一步。
实战案例2:使用mysqldump + binlog进行备份与恢复
工具优势
- 自动记录二进制日志位置:通过
--master-data参数自动记录备份时的二进制日志位置 - 数据一致性保证:通过锁表机制或事务隔离确保备份数据的一致性
- 灵活的备份范围:可选择备份整个实例、特定数据库或特定表
- 跨版本兼容性:生成的SQL文件可在不同版本的MySQL之间使用
备份语法与参数
# 基本语法
mysqldump -h 服务器 -u用户名 -p密码 [选项] 数据库名 [表名] > 备份文件.sql
核心参数说明:
-A, --all-databases:备份所有数据库-B, --databases:指定多个数据库进行备份--single-transaction:使用事务确保InnoDB表的一致性--master-data=1|2:记录二进制日志位置(1为注释,2为SQL语句)--opt:启用多种优化选项,提高备份速度-R, --routines:备份存储过程和函数-F, --flush-logs:备份前刷新二进制日志--triggers:备份触发器--events:备份事件调度器- 更多参数可查看工具说明书:mysqldump –help
全库备份实战
我们先准备两个root密码:
- 密码一:Abc@666666 当前数据库密码
- 密码二:Qaz@666666 备用密码
测试数据重新准备好,避免和之前的案例混淆
# 创建备份目录
mkdir -p /backup
# 执行全库备份,包含二进制日志位置信息(备份文件以日期命名)
mysqldump -p'Abc@666666' \
--all-databases --single-transaction \
--master-data=2 \
--flush-logs \
> /backup/`date +%F-%H`-mysql-all.sql
# 查看备份文件中的二进制日志位置信息
[root@localhost ~]# ls /backup/
2026-03-05-03-mysql-all.sql
#我们插入三条数据模仿数据变更行为
INSERT INTO company.employee5(
name, sex, hire_date, post, job_description, salary, office, dep_id
) VALUES
('lisa', 'female', CURDATE(), 'instructor', 'teach advanced', 9000.00, 501, 100),
('wangwu', 'male', CURDATE(), 'hr', 'training', 7000.00, 502, 101),
('sunny', 'female', CURDATE(), 'sale', 'sale premium', 18000.00, 503, 102);
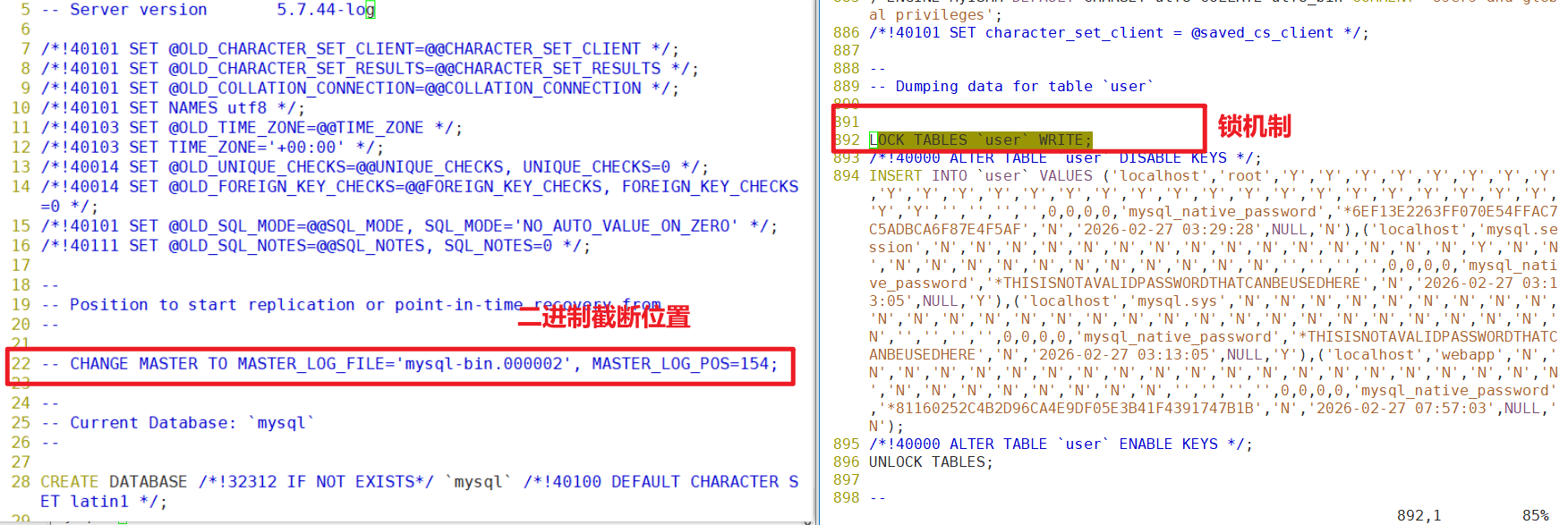
观察备份细节
- LOCK TABLES
userWRITE; ——观察各种锁机制,用来保证数据一致性 - CHANGE MASTER TO MASTER_LOG_FILE=’mysql-bin.000002′, MASTER_LOG_POS=154; ——二进制日志截断位置。第22行
- 查看备份文件:vim /backup/2026-03-05-03-mysql-all.sql
恢复实战
备份二进制日志文件
# 复制二进制日志文件到安全位置
cp /var/lib/mysql/*bin* ~/停止并清理数据库(模拟数据库损坏或全新数据库)
systemctl stop mysqld
rm -rf /var/lib/mysql/*初始化数据库并重置密码
# 启动数据库
systemctl start mysqld
# 获取临时密码(也可用以前的方法修改密码)
TEMP_PASS=$(grep 'temporary password' /var/log/mysqld.log | tail -1 | awk '{print $NF}')
# 设置新密码(使用第二个密码)
mysqladmin -uroot -p"$TEMP_PASS" password 'Qaz@666666'恢复全库备份
# 导入备份文件
mysql -p'Qaz@666666' < /backup/2026-03-05-03-mysql-all.sql
# 刷新权限
mysql -uroot -p'Qaz@666666' -e "FLUSH PRIVILEGES;"使用二进制日志恢复增量数据
从二进制日志截取记录
CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=154可以看出,二进制日志的截取位置指向日志文件mysql-bin.000002(对应偏移量 154)。# 应用二进制日志恢复数据
mysqlbinlog mysql-bin.000001 mysql-bin.000002 --start-position=154 | mysql -p'Abc@666666'
此时我们可以发现登录数据库时报错,原因是恢复数据时,也恢复了旧的密码,且我们后续增加的三条数据也恢复了。
误操作处理建议(比较少见)
当数据库因误删、误改等操作导致数据损坏或丢失时,可通过二进制日志(binlog)进行数据恢复。以下是标准操作流程及关键注意事项,可最大程度降低数据损失风险。
提取二进制日志****(通过
mysqlbinlog工具精准提取包含误操作的日志片段,避免全量日志恢复带来的冗余操作。)# 提取指定时间段的二进制日志
mysqlbinlog --start-datetime='2026-01-01 00:00:00' --stop-datetime='2026-01-02 00:00:00' ~/mysql-bin.0000* > binlog.sql编辑日志文件,移除误操作
使用文本编辑器打开
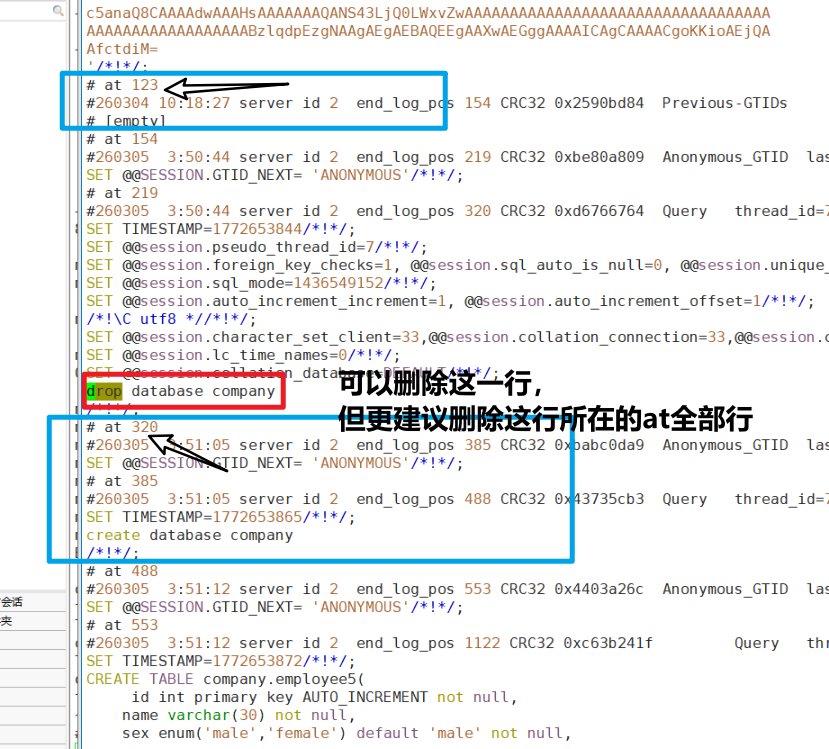
binlog.sql,按事务块删除误操作,而非仅删除单条 SQL 语句,避免事务不完整导致恢复报错。- 核心原则:二进制日志以
at事务块为单位(如截图中# at 123、# at 154等),每个at块对应一组关联的数据库操作。若误操作语句归属于at 219,需从at 219起始位置到下一个at块(如at 320)前的所有内容一并删除。 - 典型场景:若误操作是
DROP DATABASE或DELETE语句,需定位其所属的at事务块,建议完整删除该事务内的所有操作,而非仅删除目标语句。
- 核心原则:二进制日志以
应用处理后的日志
# 应用处理后的二进制日志
mysql -uroot -p'QianFeng@1234' < binlog.sql
这种操作虽并不常见,如果遇到这不失为一种办法,能尽可能的挽回损失,但恢复数据也很容易报错。
- 经过我测试发现,只是删除一条很容易在恢复时发生报错,更建议连着at一起删除,例如这条语句归属于at 219,那就从at 219删到at 320之前。
- 容易发生报错的原因可能是你在删除某条语句或者表时,后续还对相关的表或者语句有些关联的操作语句,恢复的时候虽然有报错但还是恢复成功了的。
备份策略最佳实践
备份方式选择
- 大型数据库(>100GB):优先选择Percona XtraBackup进行物理备份
- 中小型数据库:可选择mysqldump进行逻辑备份
- 混合策略:结合使用完全备份和增量/差异备份
备份计划制定
- 完全备份:每周或每月执行一次,根据数据重要性和变化频率调整
- 增量备份:每天执行,捕获日常数据变化
- 差异备份:每2-3天执行一次,平衡备份速度和恢复效率
备份验证机制
- 定期恢复测试:每月至少进行一次完整的恢复演练
- 备份文件校验:使用md5sum等工具验证备份文件完整性
- 监控备份状态:设置备份失败告警机制
备份存储策略
- 异地存储:将备份文件复制到异地服务器,防止本地灾难
- 多介质存储:结合使用磁盘、磁带等多种存储介质
- 加密存储:对敏感数据的备份进行加密处理
- 生命周期管理:制定备份文件保留策略,定期清理过期备份
自动化与监控
- 脚本自动化:使用Shell脚本和crontab实现备份自动化
- 监控系统集成:将备份状态集成到监控系统,实时掌握备份情况
- 告警机制:设置备份失败、存储空间不足等告警
总结
MySQL数据库备份是DBA日常工作中不可或缺的重要环节,直接关系到数据安全和业务连续性。本文通过详细的实战案例,演示了使用Percona XtraBackup和mysqldump两种工具进行备份和恢复的完整流程,涵盖了从安装配置到实际操作的各个环节。
在实际生产环境中,DBA应根据数据库规模、业务需求和资源状况,选择合适的备份策略和工具,并建立完善的备份验证和监控机制。定期的备份演练和策略优化,是确保在数据灾难发生时能够快速、完整恢复的关键。
一个好的备份策略不仅要能备份数据,更要能在需要时可靠地恢复数据。只有通过持续的实践和优化,才能构建起真正有效的数据安全保障体系。
