存储管理是 Linux 系统运维的核心技能之一。无论是日常的文件操作、磁盘分区,还是企业级的 RAID 配置,都离不开对存储机制的深入理解。
很多初学者对存储管理感到困惑,是因为没有建立起 “inode – block – 文件系统” 之间的关联。本文将通过层层拆解的方式,先讲透核心概念,再逐一演示实战操作,帮你构建完整的 Linux 存储知识体系,内容有点难理解很正常,可以先做个了解。
对前文的补充解释-Linux 挂载点与磁盘数据的完整关系详解
核心结论
| 操作 | /mnt/disk1 目录可见内容 | 数据实际存储位置 | 数据是否丢失 | 占用空间位置 |
|---|---|---|---|---|
| 正常挂载 sdb1 | sdb1 磁盘中的数据 | sdb1 磁盘 | 否 | sdb1 磁盘 |
| 卸载 sdb1 / 拔掉磁盘 | 根文件系统中 /mnt/disk1 目录原本的内容 | 根文件系统磁盘 | 否(sdb1 数据仍在磁盘上) | 根文件系统磁盘(原目录内容) |
| 重新挂载 sdb1 | 再次显示 sdb1 磁盘中的数据 | sdb1 磁盘 | 否 | sdb1 磁盘 |
| 删除 /mnt/disk1 目录后再插磁盘 | 目录不存在,无法直接访问 | sdb1 磁盘 | 否(数据仍在磁盘上) | 无(目录已删除) |
一句话:挂载只是 “嫁接”,不是 “复制”;数据永远在磁盘上,挂载只是建立访问路径。
举个简单的例子
我们图书馆比喻,加入挂载的概念:
- **根文件系统 (/)**:主图书馆大楼,建在第一块磁盘 (sda) 上
- /mnt/disk1 目录:主图书馆里预先留好的一个空房间,这个房间本身属于主图书馆
- sdb1 磁盘分区:一个独立的移动图书馆车,里面有自己的书架 (block)、图书卡 (inode) 和管理员 (superblock)
- 挂载操作 (mount):把移动图书馆车整个推进主图书馆的那个空房间里,并且把房间门和移动图书馆的门合二为一
- 卸载操作 (umount):把移动图书馆车从房间里推出去,恢复主图书馆那个空房间的原样
往 /mnt/disk1 写数据,影响的是哪里的空间?
当 sdb1 正常挂载在 /mnt/disk1 上时:
- 你所有对 /mnt/disk1 目录的增删改查操作,全部作用在 sdb1 磁盘上
- 这些操作不会影响根文件系统 (sda) 的任何空间
- 就像你把书放进了推进房间的移动图书馆车里,而不是主图书馆的房间里
拔掉 sdb1 或取消挂载后,/mnt/disk1 的数据还在吗?
还在,但不是你之前看到的那些数据。
这是 Linux 挂载最容易让人误解的地方:挂载会 “遮盖” 挂载点目录原本的内容。
- 在你挂载 sdb1 之前,/mnt/disk1 是根文件系统里的一个普通空目录,它本身存在于 sda 磁盘上
- 当你挂载 sdb1 后,原来的空目录被 “遮盖” 了,你看到的是 sdb1 里的内容
- 当你卸载 sdb1 或拔掉磁盘后,”遮盖” 效果消失,你看到的又变回了根文件系统里那个原本的空目录
所以:
- 你之前写入 sdb1 的数据没有丢失,它们仍然完整地保存在 sdb1 磁盘上
- 你现在在 /mnt/disk1 看到的,是根文件系统中这个目录原本的内容(通常是空的,如果里面挂载之前有文件,你会看到这些文件)
- 这些内容不占用系统内存,它们占用的是根文件系统 (sda) 的磁盘空间
重新插上磁盘,数据还在吗?
100% 还在。
数据从来没有离开过 sdb1 磁盘。你只需要重新执行挂载命令:
mount /dev/sdb1 /mnt/disk1
挂载成功后,你之前写入的所有数据都会原封不动地出现在 /mnt/disk1 目录中。
这就像你把移动图书馆车推出去又推回来,车里的书一本都不会少。
如果先删除 /mnt/disk1 目录,再插上磁盘,数据还在吗?
数据仍然完整地保存在 sdb1 磁盘上,一点都不会少。
你删除的只是主图书馆里的那个空房间,而不是移动图书馆车里的书。移动图书馆车本身是独立存在的,和主图书馆的房间没有任何关系。
你只需要重新创建那个目录,然后再次挂载即可:
# 重新创建挂载点目录
mkdir -p /mnt/disk1
# 重新挂载sdb1
mount /dev/sdb1 /mnt/disk1
所有数据都会立刻恢复访问。
完整的实验演示(你可以自己动手验证)
# 1. 先查看挂载状态
df -h /mnt/disk1
# 输出:/dev/sdb1 20G 45M 19G 1% /mnt/disk1
# 2. 在挂载的磁盘中创建一个测试文件
echo "这是sdb1磁盘里的数据" > /mnt/disk1/sdb1_data.txt
ls /mnt/disk1
# 输出:sdb1_data.txt
# 3. 卸载sdb1
umount /mnt/disk1
# 4. 再次查看/mnt/disk1目录
ls /mnt/disk1
# 输出:空(因为现在看到的是根文件系统里的空目录)
# 5. 在根文件系统的/mnt/disk1目录中创建一个文件
echo "这是根文件系统里的数据" > /mnt/disk1/root_data.txt
ls /mnt/disk1
# 输出:root_data.txt
# 6. 重新挂载sdb1
mount /dev/sdb1 /mnt/disk1
# 7. 再次查看/mnt/disk1目录
ls /mnt/disk1
# 输出:sdb1_data.txt(root_data.txt被遮盖了,看不到了)
# 8. 再次卸载sdb1
umount /mnt/disk1
# 9. 查看/mnt/disk1目录
ls /mnt/disk1
# 输出:root_data.txt(被遮盖的文件又出现了)
生产环境最常见的挂载大坑
这是 90% 的 Linux 初学者都会踩的坑,也是很多生产事故的根源:
我们要查看挂载点是否真的挂载成功
场景: 你配置了开机自动挂载 sdb1 到 /mnt/disk1,但是某次服务器重启后,sdb1 因为故障没有挂载成功。你不知情,继续往 /mnt/disk1 里写数据。
后果: 这些数据全部写到了根文件系统 (sda) 的磁盘上,占用了根分区的空间。当根分区被写满后,系统会崩溃。
更危险的是: 当你后来发现 sdb1 没有挂载,手动挂载上去后,之前写的数据会突然 “消失”(被遮盖了),你会以为数据丢了。
总结一下
挂载的本质是建立访问路径,不是复制数据。数据永远存储在对应的物理磁盘上。
挂载点目录本身属于根文件系统,挂载会遮盖它原本的内容,卸载后恢复。
卸载或拔掉磁盘不会删除磁盘上的数据,只是暂时无法访问。
删除挂载点目录不会影响磁盘上的数据,重新创建目录并挂载即可恢复。
永远不要在未挂载的挂载点目录中写入数据,这会占用根分区空间,也容易误导自己数据丢失。
文件系统详解
EXT4 文件系统
EXT4 是第四代扩展文件系统(Fourth extended filesystem),是 Linux 系统中最常用的文件系统之一。
XFS 文件系统
XFS 是一种高性能的日志文件系统,由 Silicon Graphics 开发,特别适合处理大文件和高并发 I/O 场景。
文件系统对比
| 文件系统 | 类型 | 最大容量限制 | 特点 |
|---|---|---|---|
| EXT3 | 日志文件系统 | 16TB | 第三代扩展文件系统,稳定性好 |
| EXT4 | 日志文件系统 | 16TB | 第四代扩展文件系统,性能更好 |
| XFS | 日志文件系统 | 100TB | 高性能,适合大数据场景 |
如何选择:
- 日常使用:EXT4 是默认选择,稳定可靠
- 大容量存储、数据库服务器:推荐 XFS,性能更优
核心概念:inode、block、superblock
inode(索引节点)
inode 是文件系统中最重要的概念之一,它记录了文件的元数据(metadata)。
inode 记录的信息:
- 文件的属性(大小、权限、属主、属组)
- 连接数(有多少个文件名指向这个 inode)
- 块数量、块的编号(数据存储在哪些 block 中)
- 时间戳(创建时间、修改时间、访问时间)
关键特性:
- 一个文件占用一个 inode
- inode 大小为 128 bytes(EXT4)
- inode 决定了文件系统中可以创建的文件数量
block(数据块)
block 是存储文件实际数据的单位。
关键特性:
- 存储文件的实际内容
- 大文件会占用多个 block
- block 大小默认为 4K
- block 决定了文件系统的存储容量
superblock(超级块)
superblock 是文件系统的”总管理员”,记录了整个文件系统的整体信息。
记录的信息:
- block 与 inode 的总量
- 未使用与已使用的 inode / block 数量
- block 的大小
- 文件系统的状态
block group(块组)
EXT4 文件系统将磁盘划分为多个 block group,每个 block group 包含自己的 inode table、block bitmap 和 data blocks。这种设计提高了文件系统的性能和可靠性。
这里还是举个简单例子吧
如果把整个EXT4 文件系统比作一座现代化的大型图书馆:
- 超级块 (superblock) 是图书馆的总管理处,墙上挂着全馆的总览图,记录着全馆共有多少个书架格子、多少张图书卡、已经用了多少、还剩多少,以及图书馆的开放状态和基本规则。
- 块组 (block group) 是图书馆的一个个独立楼层。为了提高效率,图书馆没有把所有书架和图书卡都堆在一个地方,而是按楼层划分,每个楼层都有自己的图书卡柜、空卡登记表、空格子登记表和书架。
- inode (索引节点) 是每本书专属的目录卡片。每张卡片上只记录这本书的关键信息:书名、作者、页数、借阅权限、存放位置(在哪个楼层的哪个书架的哪些格子里)、被多少人同时借阅过,以及创建、修改和最后被人翻阅的时间。卡片本身不包含书的任何内容。
- block (数据块) 是书架上一个个标准大小的格子。所有书的内容都存放在这些格子里,薄书可能只占 1 个格子,厚书会连续或分散占用多个格子。
- inode 位图 (inode bitmap) 是每个楼层的空卡登记表,用打勾 / 打叉的方式快速标记哪些图书卡已经被使用,哪些还是空的。
- 块位图 (block bitmap) 是每个楼层的空格子登记表,同样用打勾 / 打叉的方式快速标记哪些书架格子已经放了书,哪些还是空的。
- inode 表 (inode table) 是每个楼层存放所有图书卡的卡片柜。
完整的 “取书” 流程(对应文件读取过程)
当你(操作系统)来到图书馆,想要借一本名叫《Linux 内核设计与实现》的书(读取一个文件):
第一步:查总目录找卡片位置
你先去图书馆的总目录(目录项 dentry,它记录了文件名和 inode 号的对应关系)查找《Linux 内核设计与实现》这本书,总目录告诉你:这本书对应的图书卡编号是12345,存放在3 楼的卡片柜里。
第二步:去对应楼层取图书卡
你来到 3 楼,从3 楼的卡片柜 (inode 表) 中取出编号为 12345 的那张inode 卡片。
第三步:查看卡片上的存放信息
你仔细阅读这张卡片,上面写着:
- 这本书共 1200 页(文件大小)
- 内容存放在 3 楼书架的第 1024、1025、1026、1027 号格子里(数据块编号)
- 这本书只能被管理员修改(文件权限)
- 最后一次被人翻阅是昨天(访问时间)
第四步:按卡片指引去书架取书
你按照卡片上的指引,依次走到 3 楼书架的 1024、1025、1026、1027 号格子前,把每个格子里的书页都取出来,按顺序拼在一起,就得到了完整的《Linux 内核设计与实现》这本书。
实战:inode 与 block 的关系
问题一:新分区中,文件的数量和什么有关系?
答案:inode 数量决定了文件系统中可以创建的文件数量。
验证实验:
# 1. 观察某个分区中的 inode 节点数
df -i
输出示例:
[root@localhost ~]# df -i
文件系统 Inode 已用(I) 可用(I) 已用(I)% 挂载点
/dev/mapper/centos-root 8910848 128338 8782510 2% /
devtmpfs 120221 405 119816 1% /dev
tmpfs 124486 1 124485 1% /dev/shm
tmpfs 124486 914 123572 1% /run
tmpfs 124486 16 124470 1% /sys/fs/cgroup
/dev/sda1 524288 340 523948 1% /boot
tmpfs 124486 9 124477 1% /run/user/42
tmpfs 124486 1 124485 1% /run/user/0
/dev/sdb1 51200 11 51189 1% /mnt/disk1
# 这里我们着重看sdb1这块磁盘
# 在sdb1上创建一个文件
[root@localhost ~]# touch /mnt/disk1/1.txt
[root@localhost ~]# df -i
文件系统 Inode 已用(I) 可用(I) 已用(I)% 挂载点
/dev/sdb1 51200 12 51188 1% /mnt/disk1
你会发现 IUsed(已用I) 增加了 1,说明创建一个文件会消耗一个 inode。
# 4. 创造大量文件,观察 inode 使用情况
[root@localhost ~]# touch /mnt/disk1/file{1..51188}
[root@localhost ~]# df -i
文件系统 Inode 已用(I) 可用(I) 已用(I)% 挂载点
/dev/sdb1 51200 51200 0 100% /mnt/disk1
# 请问写满之后,还能否创建新文件呢?
[root@localhost ~]# touch /mnt/disk1/txt
touch: 无法创建"/mnt/disk1/txt": 设备上没有空间
# 能否向已存在的文件中写入内容呢?答案是?
[root@localhost ~]# echo 666 > /mnt/disk1/file1
[root@localhost ~]# cat /mnt/disk1/file1
666
结论:
- inode 决定了文件系统中文件的数量
- 即使还有磁盘空间,如果 inode 用完了,也无法创建新文件
- inode消耗的是文件数量,并非空间存储大小,可以继续存储内容
问题二:当分区空间大小消耗完毕,还能否新增文件?
答案:不能,block 用完后无法存储新数据。
验证实验:
# 1. 向目标分区写入大量数据,填满磁盘
[root@localhost ~]# dd if=/dev/zero of=/mnt/disk1/file1 bs=1k count=100000000
dd: 写入"/mnt/disk1/file1" 出错: 设备上没有空间
记录了187125+0 的读入
记录了187124+0 的写出
191614976字节(192 MB)已复制,0.457181 秒,419 MB/秒
# 2. 查看目标sdb1分区容量,已满
[root@localhost ~]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root xfs 17G 3.6G 14G 21% /
devtmpfs devtmpfs 470M 0 470M 0% /dev
tmpfs tmpfs 487M 0 487M 0% /dev/shm
tmpfs tmpfs 487M 8.3M 478M 2% /run
tmpfs tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/sda1 xfs 1014M 166M 849M 17% /boot
tmpfs tmpfs 98M 12K 98M 1% /run/user/42
tmpfs tmpfs 98M 0 98M 0% /run/user/0
/dev/sdb1 ext4 190M 186M 0 100% /mnt/disk1
# 3. 尝试创建新文件
[root@localhost ~]# touch /mnt/disk1/txt
touch: 无法创建"/mnt/disk1/txt": 设备上没有空间
# 4.留出一个inode,创建文件并写入数据
[root@localhost ~]# rm -rf /mnt/disk1/file2
[root@localhost ~]# touch /mnt/disk1/txt
[root@localhost ~]# echo 1111 > /mnt/disk1/txt
-bash: echo: 写错误: 设备上没有空间
结论:
- 磁盘空间的限制根据 inode 和 block 两方面
- inode决定文件数量却不会影响存储,block也决定存储空间却不会影响文件数量
- 如果存储用完可以创建文件却不能写入数据,而文件数量用完却可以在已有的文件中写入数据。
| 限制因素 | 决定内容 |
|---|---|
| inode | 文件数量上限 |
| block | 存储空间上限 |
提示:请定期清理磁盘空间,避免 inode 或 block 耗尽导致系统报错。
文件链接
文件链接是 Linux 系统中非常重要的概念,它允许我们为一个文件创建多个”入口”。Linux 支持两种类型的链接:软链接和硬链接。
符号链接(软连接)
软链接(symbolic link) 类似于 Windows 中的快捷方式,它记录的是源文件的路径。
创建软链接
# 1. 创建一个文件,并输入内容
[root@localhost ~]# echo 123456789 > /aaa
# 2. 创建一个软连接
root@localhost ~]# ln -s /aaa aaa
# -s 表示创建软连接
# 3. 观察软连接
[root@localhost ~]# ll aaa
lrwxrwxrwx. 1 root root 4 5月 18 15:23 aaa -> /aaa
# 注意开头的 'l' 表示这是一个链接文件
查看源文件和软链接
# 4. 观察软连接和源文件
[root@localhost ~]# ll aaa /aaa
lrwxrwxrwx. 1 root root 4 5月 18 15:23 aaa -> /aaa
-rw-r--r--. 1 root root 10 5月 18 15:23 /aaa
# 5. 查看两个文件,内容一致
[root@localhost ~]# cat aaa
123456789
[root@localhost ~]# cat /aaa
123456789
删除源文件
# 6. 删除源文件,软连接失效
[root@localhost ~]# rm -rf /aaa
[root@localhost ~]# ll aaa
lrwxrwxrwx. 1 root root 4 5月 18 15:23 aaa -> /aaa
[root@localhost ~]# cat aaa
cat: aaa: 没有那个文件或目录
# 软连接仍然存在,但指向的路径已经不存在,变成"死链接"

软链接的特点
| 特性 | 说明 |
|---|---|
| 类似快捷方式 | 软链接就像 Windows 的快捷方式 |
| 可跨分区 | 可以对任何文件和目录做软连接,不受分区限制 |
| 记录路径 | 软链接记录的只是源文件的路径 |
| 源文件删除后失效 | 失去源文件后,软连接不可用 |
| 独立 inode | 软链接有自己独立的 inode |
硬链接
硬链接 是指多个文件名指向同一个 inode。它与软链接有本质的区别。
创建硬链接
# 1. 创建一个文件
[root@localhost ~]# echo "222" > /file2
# 2. 在同分区创建硬链接(成功)
[root@localhost ~]# ln /file2 /file2-h1
# 3. 尝试跨分区在sdb1上创建硬链接(失败)
[root@localhost ~]# ln /file2 /mnt/disk1/file2-h2
ln: 无法创建硬链接"/mnt/disk1/file2-h2" => "/file2": 无效的跨设备连接
注意:硬链接只能在同一个分区内创建,不能跨分区。
删除源文件
# 4. 删除源文件,硬链接依然可用
[root@localhost ~]# rm -rf /file2
[root@localhost ~]# cat /file2-h1
222
# 硬链接不受源文件删除的影响
目录不允许创建硬链接
[root@localhost ~]# ln /home/ /mnt
ln: "/home/": 不允许将硬链接指向目录
硬链接的特点
| 特性 | 说明 |
|---|---|
| 只能针对文件 | 不能对目录创建硬链接 |
| 只能同分区 | 硬链接只能在同一个文件系统内创建 |
| 共享 inode | 硬链接和源文件共享同一个 inode |
| 源文件删除不影响 | 删除源文件后,硬链接依然可用 |
软链接 vs 硬链接
| 对比项 | 软链接 | 硬链接 |
|---|---|---|
| 本质 | 记录源文件路径 | 与源文件共享 inode |
| 跨分区 | ✅ 可以 | ❌ 不可以 |
| 目录链接 | ✅ 可以 | ❌ 不可以 |
| 源文件删除 | ❌ 失效 | ✅ 依然可用 |
| inode | 独立 inode | 共享 inode |
| 文件大小 | 存储路径的长度 | 与源文件相同 |
| 类似概念 | Windows 快捷方式 | 文件的”别名” |
RAID 磁盘阵列
RAID 简介
RAID 全称是 廉价磁盘冗余阵列(Redundant Array of Independent Disks)。
作用:
- 容错:某块硬盘损坏时,数据不会丢失
- 提升读写速率:多块硬盘同时工作,提高 I/O 性能
常见 RAID 类型
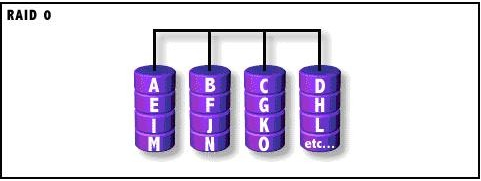
RAID 0(条带集)
| 特性 | 说明 |
|---|---|
| 磁盘数量 | 2 块及以上 |
| 读写性能 | 100% × N(最快) |
| 容错能力 | ❌ 不容错 |
| 空间利用率 | 100% |
特点:数据分散存储在多块磁盘上,读写速度最快,但任何一块磁盘损坏都会导致数据丢失。
怎么运作?
数据拆开平均分到每块盘,同时读写。
- 文件 1 前一半放 A 盘,后一半放 B 盘
- 文件 2 前一半放 B 盘,后一半放 A 盘
- 两块盘同时干活,速度翻倍
举例:
你有 2 个抽屉,把一本书撕成两半,左边放抽屉 1,右边放抽屉 2。
拿书时两个抽屉同时拿,速度更快。
故障会怎样?
只要坏 1 块盘,全部数据直接没了。
抽屉 1 坏了,左边书页全丢,整本书报废。
能不能换盘救数据?
❌ 不能。坏一块全盘报废,换新盘也救不回来,数据直接丢失。
RAID 1(镜像集)

| 特性 | 说明 |
|---|---|
| 磁盘数量 | 2 块 |
| 读写性能 | 一般 |
| 容错能力 | ✅ 容错 |
| 空间利用率 | 50% |
特点:数据完整复制到两块磁盘上,一块损坏不影响数据读取,但存储空间只有一半可用。
怎么运作?
每块盘存一模一样完整数据,互相备份。
- A 盘存:文件 1、文件 2、文件 3
- B 盘也完整存:文件 1、文件 2、文件 3
举例:
2 个抽屉,两本一模一样的书,抽屉 1 一本,抽屉 2 一本。
不管拿哪个抽屉,都能拿到完整的书。
故障会怎样?
坏任意 1 块盘,数据完全没事。
抽屉 1 坏了,抽屉 2 还有完整的书,正常使用。
能不能换盘救数据?
✅ 可以,数据不丢
- 拔掉坏盘
- 插上新硬盘
- 系统自动把好盘的数据完整复制到新盘
- 阵列恢复正常,全程数据不丢
缺点:2 块盘只能用 1 块盘的容量,100G+100G 只能用 100G。
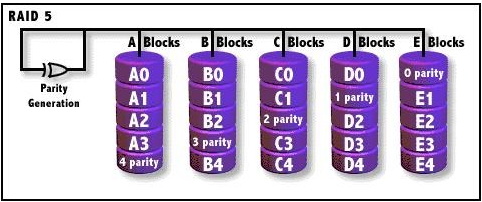
RAID 5(带奇偶校验条带集)
| 特性 | 说明 |
|---|---|
| 磁盘数量 | 3 块及以上 |
| 读写性能 | 快 |
| 容错能力 | ✅ 容错(允许 1 块磁盘损坏) |
| 空间利用率 | (n-1)/n |
特点:数据和校验信息分散存储在所有磁盘上,兼顾性能和容错,是最常用的 RAID 级别。
怎么运作?
数据 + 校验信息分开存在所有盘,不单独放一块盘
最少需要 3 块盘。
- A 盘:文件 1
- B 盘:文件 2
- C 盘:文件 1 + 文件 2 的校验码(用来恢复数据)
下一轮轮换:
- A 盘:校验码
- B 盘:文件 3
- C 盘:文件 4
举例:
3 个抽屉,2 本不同的书 + 1 张 “复原笔记”
笔记可以根据两本书算出任意一本丢了的内容。
也可以理解为1+2=3(每个数字代表一个磁盘代号),有一天2坏了变成了1+?=3,插上新磁盘后阵列会自动算出2这个数字。
故障会怎样?
最多允许坏 1 块盘,坏 2 块直接报废。
坏任意一块,靠另外两块盘的数据 + 校验码,算出丢失内容,正常读写。
能不能换盘救数据?
✅ 可以,数据不丢
- 拔掉坏盘
- 插入新硬盘
- RAID 自动用剩下两块盘,算出丢失数据,同步到新盘
- 阵列修复完成,继续正常使用
特点:3 块盘用 2 块容量,100+100+100 = 可用 200G,企业最常用。
硬 RAID vs 软 RAID
| 对比项 | 硬 RAID | 软 RAID |
|---|---|---|
| 实现方式 | 需要 RAID 卡 | 通过操作系统实现 |
| 处理速度 | 有独立 CPU,速度快 | 依赖系统 CPU |
| 成本 | 较高 | 较低 |
| 适用场景 | 企业级服务器 | 个人电脑、测试环境 |

软 RAID 实战示例
准备磁盘
# 查看系统中的磁盘
[root@localhost ~]# ll /dev/sd*
brw-rw----. 1 root disk 8, 32 5月 19 11:37 /dev/sdc
brw-rw----. 1 root disk 8, 48 5月 19 11:37 /dev/sdd
brw-rw----. 1 root disk 8, 64 5月 19 11:37 /dev/sde
brw-rw----. 1 root disk 8, 80 5月 19 11:37 /dev/sdf
我们准备了 4 块磁盘:/dev/sdc、/dev/sdd、/dev/sde、/dev/sdf
使用RAID 管理工具创建 RAID 5
# RAID5: (3块数据盘) + (1块热备硬盘)
[root@localhost ~]# mdadm -C /dev/md0 -l5 -n3 -x1 /dev/sd{c,d,e,f}
参数说明:
| 参数 | 说明 |
|---|---|
-C | 创建 RAID |
/dev/md0 | 第一个 RAID 设备 |
-l5 | RAID 5 |
-n3 | RAID 成员的数量(3 块) |
-x1 | 热备磁盘的数量(1 块) |
格式化并挂载
# 格式化
[root@localhost ~]# mkfs.ext4 /dev/md0
# 创建挂载点
[root@localhost ~]# mkdir /mnt/raid5
# 挂载
[root@localhost ~]# mount /dev/md0 /mnt/raid5
# 测试写入数据
[root@localhost ~]# cp -rf /etc /mnt/raid5/etc1
查看 RAID 信息
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0: # 软RAID设备名称
Version : 1.2 # RAID元数据版本
Creation Time : Wed May 20 10:33:57 2026 # 创建时间
Raid Level : raid5 # RAID级别:RAID5
Array Size : 41908224 (39.97 GiB 42.91 GB) # 阵列总可用容量
Used Dev Size : 20954112 (19.98 GiB 21.46 GB) # 每块盘实际使用容量
Raid Devices : 3 # 正常工作的RAID成员盘数量(RAID5需要3块)
Total Devices : 4 # 阵列中总磁盘数(3个工作 + 1个热备)
Persistence : Superblock is persistent # 超级块持久化,重启不丢配置
Update Time : Wed May 20 10:35:29 2026 # 最后更新时间
State : active # 阵列状态:正常活跃
Active Devices : 3 # 活跃工作的磁盘数
Working Devices : 4 # 正常运行的磁盘总数
Failed Devices : 0 # 损坏磁盘数:0,无坏盘
Spare Devices : 1 # 热备盘数量:1块
Layout : left-symmetric # RAID5数据布局方式(默认)
Chunk Size : 512K # 数据块大小(条带大小)
Consistency Policy : resync # 一致性策略:同步
Name : localhost.localdomain:0 (local to host localhost.localdomain) # 阵列名称
UUID : 6ef1a84e:c593e6b3:01ca15fa:fe5b7711 # 阵列唯一ID
Events : 19 # 阵列事件计数(操作次数)
Number Major Minor RaidDevice State
0 8 32 0 active sync /dev/sdc # 活跃成员盘
1 8 48 1 active sync /dev/sdd # 活跃成员盘
4 8 64 2 active sync /dev/sde # 活跃成员盘
3 8 80 - spare /dev/sdf # 热备盘(空闲待命)
模拟硬盘损坏
# 终端一:持续查看 RAID 状态
[root@localhost ~]# watch -n 0.5 'mdadm -D /dev/md0 | tail'
# 终端二:模拟一块硬盘损坏并移除
[root@localhost ~]# mdadm /dev/md0 -f /dev/sde -r /dev/sde
# -f: 标记为失败 (fail)
# -r: 移除 (remove)
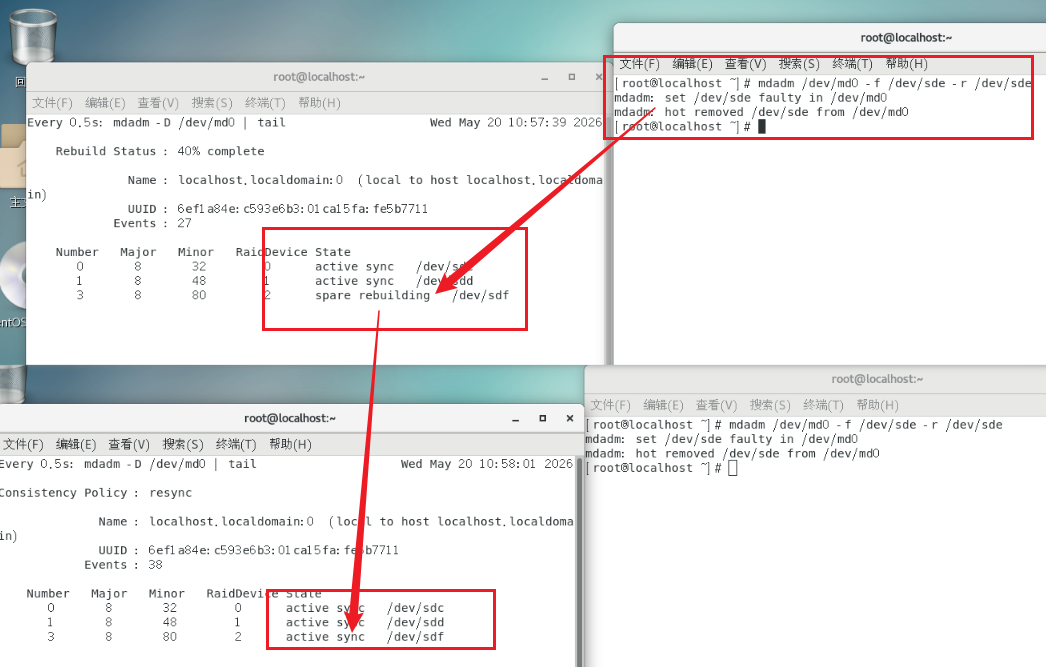
观察结果:热备磁盘
/dev/sdf会自动顶替损坏的磁盘,RAID 5 继续正常工作。
总结
通过本文的学习,你应该掌握了:
- 理解 EXT4 和 XFS 文件系统的特点和适用场景
- 掌握 inode、block、superblock 的核心概念
- 理解 inode 决定文件数量,block 决定存储容量的原理
- 掌握软链接和硬链接的区别和使用场景
- 了解 RAID 0、RAID 1、RAID 5 的特点和适用场景
- 能够使用 mdadm 创建和管理软 RAID
学习建议:存储管理是 Linux 运维的核心技能之一,建议在自己的虚拟机上多练习这些命令,通过实际操作来加深理解。特别是 inode 和 block 的关系、软链接和硬链接的区别,建议动手实验来加深印象。
