进程是操作系统最核心的抽象概念之一,是资源分配的基本单位,也是所有程序执行的载体。理解进程的本质、生命周期和管理机制,是深入掌握 Linux 系统的必经之路。
很多初学者觉得进程管理抽象难懂,是因为没有建立起 “程序 – 进程 – 系统资源” 之间的关联。本文将通过层层拆解的方式,先讲透核心概念,再逐一演示 ps、top、htop 等常用工具的实战用法,帮你构建完整的 Linux 进程知识体系。
进程简介
灵魂三问
在深入了解进程之前,让我们先思考三个哲学问题:
- 我是谁? → 进程是什么?
- 我从哪里来? → 进程从哪里来?
- 我要到哪里去? → 进程要到哪里去?
什么是进程?
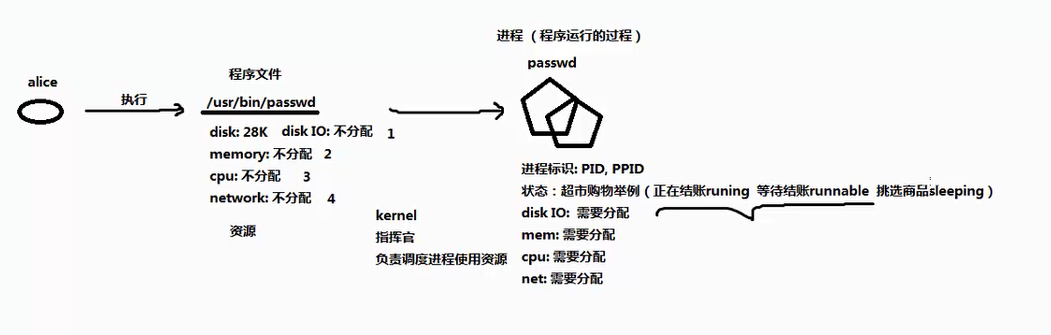
进程(Process)是已启动的可执行程序的运行实例。
举个简单例子说明一下
如果把程序比作一本”菜谱”,那么进程就是”按照菜谱做菜的过程”。菜谱本身是静态的,放在书架上不会有任何变化;但当你开始按照菜谱操作时,就进入了一个动态的过程——你需要准备食材、控制火候、掌握时间,这就是进程。
进程的核心组成:
- 已分配内存的地址空间
- 安全属性(包括所有权凭据和特权)
- 程序代码的一个或多个执行线程
- 进程状态
程序 vs 进程
| 类型 | 说明 | 示例 |
|---|---|---|
| 程序 | 二进制文件,静态的 | /usr/bin/passwd、/usr/sbin/useradd |
| 进程 | 程序运行的过程,动态的,有生命周期及运行状态 | 运行中的 passwd 命令 |
- 程序就像你手机里安装的微信APP,它躺在你的存储空间里,不会消耗什么资源
- 进程就像你打开微信正在聊天,这时候它占用了内存、CPU,还有网络连接
进程的生命周期
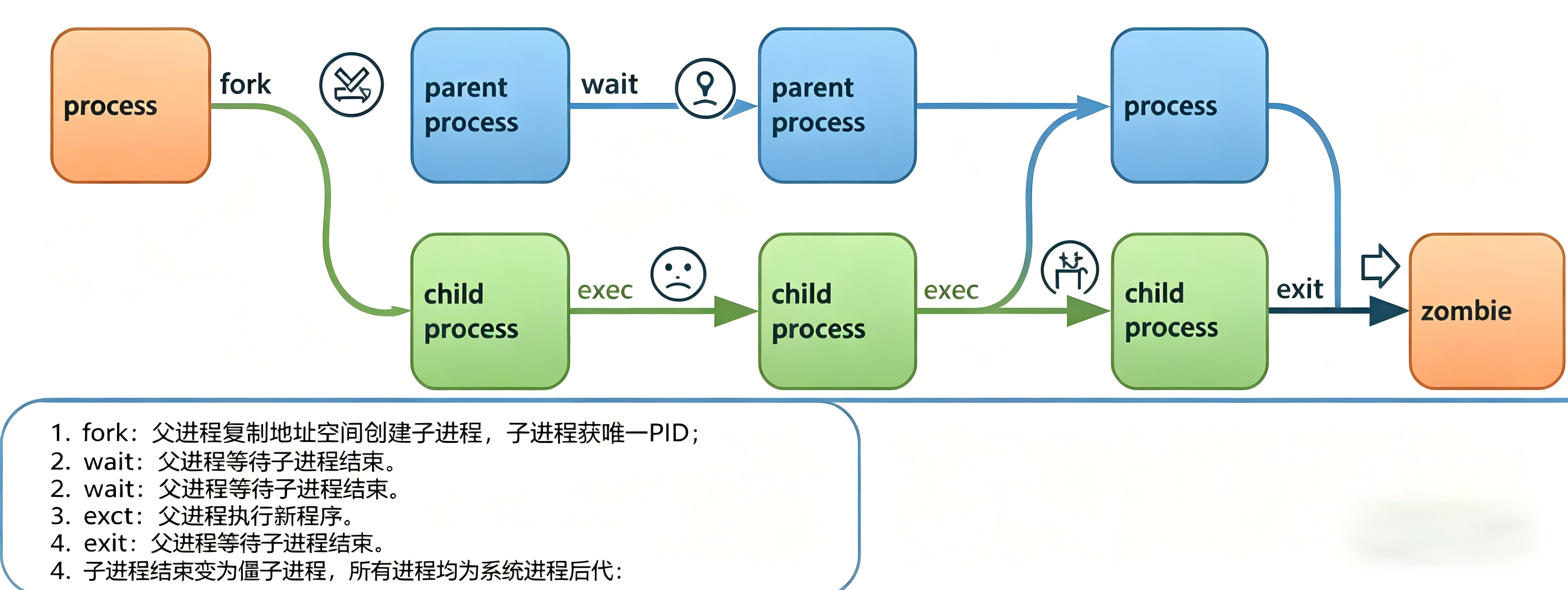
父进程通过 fork() 复制自己的地址空间来创建一个新的子进程。关键特性:
- 每个新进程分配一个唯一的进程 ID(PID),用于跟踪和安全性
- 任何进程都可以创建子进程
- 所有进程都是第一个系统进程的后代:
- CentOS 5/6:
init - CentOS 7+:
systemd
- CentOS 5/6:
简单举个例子理解:
进程的关系就像一个大家族:
systemd (PID 1, 家族老祖宗)
├── sshd (PID 1234, 大儿子)
│ └── bash (PID 5678, 孙子)
│ └── vim (PID 9012, 曾孙)
├── httpd (PID 2345, 二儿子)
│ ├── httpd (PID 2346, 孙子)
│ └── httpd (PID 2347, 孙子)
└── crond (PID 3456, 三儿子)
└── sh (PID 4567, 孙子)
- PID(Process ID):相当于每个人的身份证号,唯一标识
- PPID(Parent Process ID):相当于父亲的身份证号,记录你从哪里来
- 系统启动时,第一个进程是
systemd(PID=1),它是所有进程的”祖先”
进程状态
为什么会有进程状态?
在多任务处理操作系统中,每个 CPU(或核心)在一个时间点上只能处理一个进程。在进程运行时,它对 CPU 时间和资源分配的要求会不断变化,因此需要为进程分配一个状态,它随着环境要求而改变。
简单举例说明:
想象一个餐厅只有一个厨师(单核CPU),但有很多订单(进程)。厨师需要不断地在各个订单之间切换:
- 有的订单正在炒(运行状态 R)
- 有的在等待食材(睡眠状态 S)
- 有的被客人要求暂停(停止状态 T)
- 有的已经做完但客人还没来取(僵尸状态 Z)
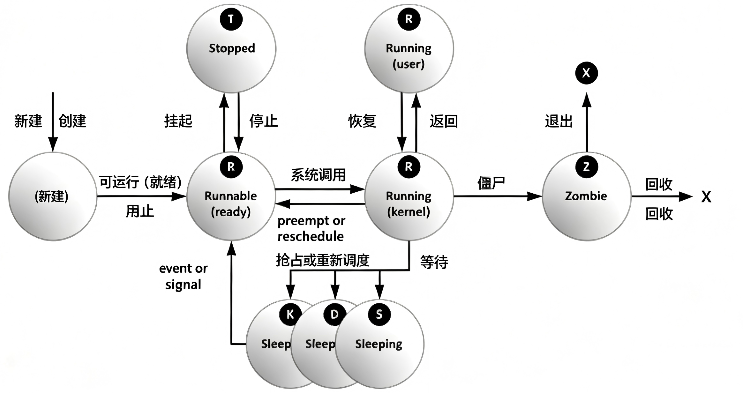
常见进程状态
| 状态名称 | 标志 | 内核定义状态名及中文说明 |
|---|---|---|
| 运行中 | R | TASK_RUNNING:进程要么正在 CPU 上执行,要么等待运行。进程可以执行用户代码或内核代码(系统调用),也可以处于就绪队列中等待被调度。 |
| 睡眠中 | S | TASK_INTERRUPTIBLE(可中断睡眠):进程正在等待某个条件满足:硬件请求、系统资源访问或信号。当事件或信号满足条件时,进程会立即返回到运行状态。 |
| 睡眠中 | D | TASK_UNINTERRUPTIBLE(不可中断睡眠):进程同样处于睡眠状态,但与 S 状态不同,完全不响应任何信号。仅用于进程中断会导致硬件设备进入不可预测状态的特殊场景(如磁盘 IO 操作)。 |
| 睡眠中 | K | TASK_KILLABLE(可杀死睡眠):功能与不可中断 D 状态完全一致,但增加了对 “杀死信号” 的响应能力。大多数系统工具仍会将其显示为 D 状态。 |
| 已停止 | T | TASK_STOPPED:进程已被暂停(挂起),通常由用户或其他进程发送信号触发。可以通过发送继续信号让进程恢复运行。 |
| 已跟踪 | T | TASK_TRACED:正在被调试器跟踪的进程会临时进入停止状态,与 TASK_STOPPED 共享同一个 T 标志。 |
| 僵尸 | Z | EXIT_ZOMBIE:子进程已经执行完毕并退出,向父进程发送了退出信号。除了进程 ID(PID)和退出状态信息外,所有其他资源都已被释放。 |
| 已销毁 | X | EXIT_DEAD:父进程调用wait()系统调用完成了对僵尸进程的资源回收,进程结构被完全释放。此状态永远不会出现在 ps、top 等任何进程查看工具中。 |
进程管理工具
目标
通过进程管理工具,我们可以了解:
- PID(进程ID)和 PPID(父进程ID)
- 当前的进程状态
- 内存的分配情况
- CPU 和已花费的实际时间
- 用户 UID(决定进程的特权)
- 进程名称
静态查看进程 – ps
ps = Process Status(不是 Photoshop 嗷!)
这款工具就类似于Windows的任务管理器,
ps与Windows任务管理器显著的区别就是你看到的是你敲出命令回车的那一瞬间进程的信息,并不会实时动态更新
基本用法
# 查看系统所有进程的前两行
ps aux | head -2
输出示例:
这里只显示了一个进程的信息,第一行则是对应第二行的各项指标
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.4 0.2 128260 2636 ? Ss 11:33 0:01 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
命令参数说明
| 参数 | 说明 |
|---|---|
a | 显示现行终端机下的所有程序 |
u | 以用户为主的格式来显示程序状况 |
x | 不以终端机来区分 |
ps aux 输出字段详解
| 字段 | 说明 | 比喻 | 实际值(PID=1 的 systemd 进程) |
|---|---|---|---|
| USER | 运行进程的用户 | 这道菜是哪个厨师负责的 | root |
| PID | 进程 ID(云工程师靠 PID 来管理进程) | 进程的唯一身份证号 | 1 |
| %CPU | CPU 占用率 | 这道菜占用了厨师多少精力 | 0.4% |
| %MEM | 内存占用率 | 这道菜占用了厨房多少空间 | 0.2% |
| VSZ | 占用虚拟内存 | 申请了多大的厨房操作台 | 128260 KB |
| RSS | 占用实际内存 | 实际使用了多大的操作台 | 2636 KB |
| TTY | 进程运行的终端 | 在哪个厨房做的菜 | ?(无关联终端,系统守护进程) |
| STAT | 进程状态 | 菜现在的状态(正在炒 / 等待 / 完成) | Ss(S:可中断睡眠;s:会话首进程) |
| START | 进程的启动时间 | 什么时候开始做这道菜的 | 11:33 |
| TIME | 进程占用 CPU 的总时间(格式:分钟:秒) | 厨师在这道菜上花了多少时间 | 0:01 |
| COMMAND | 进程文件 / 进程名 | 菜名是什么 | /usr/lib/systemd/systemd –switched-root –system –deserialize 22 |
小提醒:VSZ 和 RSS 的区别
- VSZ(虚拟内存):相当于你租了一个 100 平米的仓库,但只用了 30 平米
- RSS(实际内存):你实际使用的 30 平米
进程排序
# 以 CPU 占比降序排列(减号表示降序)
ps aux --sort -%cpu
# 以 CPU 占比升序排列
ps aux --sort %cpu
# 以内存使用率降序排列
ps aux --sort -%mem
使用场景:
- 当服务器变慢时,可以用
ps aux --sort -%cpu快速找到占用 CPU 最高的进程 - 当内存不足时,可以用
ps aux --sort -%mem找到占用内存最多的进程
查看进程的父子关系
ps -ef
部分输出示例:
[root@localhost ~]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 11:33 ? 00:00:01 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0 0 11:33 ? 00:00:00 [kthreadd]
root 3 2 0 11:33 ? 00:00:00 [ksoftirqd/0]
root 5 2 0 11:33 ? 00:00:00 [kworker/0:0H]
root 3111 1 0 11:33 ? 00:00:00 /usr/lib/systemd/systemd-journald
root 3132 1 0 11:33 ? 00:00:00 /usr/sbin/lvmetad -f
root 3143 1 0 11:33 ? 00:00:00 /usr/lib/systemd/systemd-udevd
root 4962 2 0 11:33 ? 00:00:00 [kworker/u257:0]
root 4970 2 0 11:33 ? 00:00:00 [hci0]
注意观察 PID 和 PPID 的关系:
- PID 是当前进程 ID
- PPID 是父进程 ID
- 例如 PID=3 的进程,它的父进程是 PID=2
自定义显示字段(高级)
# 只显示指定的字段
ps axo user,pid,ppid,%mem,command | tail -3
输出示例:
[root@localhost ~]# ps axo user,pid,ppid,%mem,command | tail -3
root 9279 6720 0.0 sleep 60
root 9415 9008 0.1 ps axo user,pid,ppid,%mem,command
root 9416 9008 0.1 bash
动态查看进程 – top
top命令就像 Linux 的任务管理器
如果说ps像Linux的静态任务管理器,那么top就是动态的Linux任务管理器
启动与退出
- 启动:直接在终端输入
top后回车 - 退出:按
q键
上半部分 – 系统概览
top - 11:59:10 up 25 min, 2 users, load average: 0.14, 0.05, 0.06
Tasks: 211 total, 2 running, 209 sleeping, 0 stopped, 0 zombie
%Cpu(s): 18.6 us, 2.0 sy, 0.0 ni, 79.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 995892 total, 65896 free, 675788 used, 254208 buff/cache
KiB Swap: 2097148 total, 2036220 free, 60928 used. 87648 avail Mem
逐行解析
第一行:系统时间和负载
top - 11:59:10 up 25 min, 2 users, load average: 0.14, 0.05, 0.06
| 字段 | 实际值 | 详细说明 | 通俗理解 |
|---|---|---|---|
当前系统时间 | 11:59:10 | 执行 top 命令时的系统时钟时间 | 现在几点了 |
系统运行时间 | up 25 min | 系统从开机到现在连续运行了 25 分钟 | 电脑开机多久了 |
| 登录用户数 | 2 users | 当前有 2 个用户登录到系统(包括本地终端和远程 SSH) | 有几个人在用这台电脑 |
| 1 分钟平均负载 | 0.14 | 过去 1 分钟内,等待 CPU 执行的平均任务数 | 最近 1 分钟,厨师平均要同时做 0.14 道菜 |
| 5 分钟平均负载 | 0.05 | 过去 5 分钟内,等待 CPU 执行的平均任务数 | 最近 5 分钟,厨师平均要同时做 0.05 道菜 |
| 15 分钟平均负载 | 0.06 | 过去 15 分钟内,等待 CPU 执行的平均任务数 | 最近 15 分钟,厨师平均要同时做 0.06 道菜 |
什么是 Load Average?
把 CPU 比作一座桥,load average 就是桥上正在通行的车辆数量。
- 如果桥有 4 条车道(4 核 CPU),load average = 2 表示桥很空闲
- load average = 4 表示桥刚好饱和
- load average = 8 表示桥上已经堵车了,车辆在排队等待
三个数值分别代表:最近 1 分钟、5 分钟、15 分钟的平均负载。如果 1 分钟的负载远高于 15 分钟,说明系统负载在上升。
第二行:进程统计
Tasks: 211 total, 2 running, 209 sleeping, 0 stopped, 0 zombie
| 字段 | 实际值 | 详细说明 |
|---|---|---|
| 总进程数 | 211 | 系统中当前运行的所有进程总数 |
| 运行中进程 | 2 | 正在 CPU 上执行或等待 CPU 调度的进程数(对应 R 状态) |
| 睡眠中进程 | 209 | 等待某个事件发生的进程数(对应 S/D/K 状态,绝大多数进程都处于此状态) |
| 已停止进程 | 0 | 被暂停执行的进程数(对应 T 状态,如被调试器暂停) |
| 僵尸进程 | 0 | 已执行完毕但父进程未回收资源的进程数(对应 Z 状态) |
正常情况下,大部分进程都处于 sleeping 状态,这是正常的,因为它们只是在等待某个事件(如用户输入、网络数据等)。
第三行:CPU 使用情况
%Cpu(s): 18.6 us, 2.0 sy, 0.0 ni, 79.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
| 字段 | 含义 | 说明 |
|---|---|---|
us | 用户空间 | 用户程序占用的 CPU |
sy | 内核空间 | 系统内核占用的 CPU |
ni | nice 值调整 | 改变过优先级的进程占用 CPU |
id | idle(空闲) | CPU 空闲百分比 |
wa | wait(等待) | 等待磁盘 I/O 的 CPU 时间 |
hi | 硬中断 | 硬件中断服务占用 |
si | 软中断 | 软件中断服务占用 |
st | steal(被偷走) | 虚拟机被宿主机偷走的 CPU 时间 |
把你的 CPU 比作你一天的时间
us:你用来做工作的时间sy:你用来处理生活琐事的时间(买菜、做饭)id:你发呆、休息的时间wa:你等快递、等外卖的时间(在等待,什么都做不了)st:你的时间被老板偷偷占用(加班但没算加班费)
第四行:物理内存统计
KiB Mem : 995892 total, 65896 free, 675788 used, 254208 buff/cache
| 字段 | 实际值 | 换算 | 详细说明 |
|---|---|---|---|
| 总内存 | 995892 KiB | ~972 MB | 系统安装的物理内存总量 |
| 空闲内存 | 65896 KiB | ~64 MB | 完全未被使用的内存 |
| 已用内存 | 675788 KiB | ~660 MB | 被进程和系统占用的内存 |
| 缓存 / 缓冲区 | 254208 KiB | ~248 MB | 系统用来加速磁盘读写的缓存(可被回收给应用程序使用) |
不要只看
free值判断内存是否够用!Linux 会尽可能利用空闲内存做缓存,真正可用的内存是free + buff/cache。
第五行:交换分区统计
KiB Swap: 2097148 total, 2036220 free, 60928 used. 87648 avail Mem
| 字段 | 实际值 | 换算 | 详细说明 |
|---|---|---|---|
| 总交换空间 | 2097148 KiB | ~2 GB | 硬盘上划分的虚拟内存分区大小 |
| 空闲交换空间 | 2036220 KiB | ~1.94 GB | 未被使用的交换空间 |
| 已用交换空间 | 60928 KiB | ~59 MB | 被换出到硬盘的内存大小 |
| 可用内存 | 87648 KiB | ~85 MB | 系统估算的、可立即分配给新进程的最大内存(最准确的可用内存指标) |
下半部分 – 进程详情(这里列举进程8290说明)

| 字段 | 说明 | 通俗比喻 | 你的实际值(PID=8290) | 补充说明 |
|---|---|---|---|---|
| PID | 进程 ID | 进程的唯一身份证号 | 8290 | 系统中每个进程都有一个独一无二的 PID,杀死、管理进程都靠它 |
| USER | 运行进程的用户 | 这个任务的负责人 | root | 表示该进程是由 root 用户启动的 |
| PR | 进程优先级 | 任务的紧急程度 | 20 | 内核调度优先级,值越小优先级越高,范围 0-39 |
| NI | Nice 值 | 任务的 “谦让度” | 0 | 优先级调整值,范围 -20(最高)到 19(最低)。普通用户只能调大 NI(降低优先级),root 可任意调整 |
| VIRT | 虚拟内存使用量 | 申请了多大的办公室 | 2788116 KiB ≈ 2.66 GB | 进程申请的全部地址空间,包括:实际使用的内存、交换区、共享库、未使用的内存。数值通常很大,不代表实际内存占用 |
| RES | 常驻内存使用量 | 实际在用的办公面积 | 197780 KiB ≈ 193 MB | 进程实际占用的物理内存,是判断内存占用的核心指标 |
| SHR | 共享内存大小 | 和同事共用的会议室 | 53652 KiB ≈ 52 MB | 多个进程可以共享的内存(如系统库文件、共享数据)。计算系统总内存占用时,不能简单把所有进程的 RES 相加,因为 SHR 部分是重复计算的 |
| S | 进程状态 | 任务当前在做什么 | R(运行中) | 和 ps aux 的 STAT 字段一致:- R:运行 / 就绪- S:可中断睡眠- D:不可中断睡眠- Z:僵尸- T:停止 |
| %CPU | CPU 使用率 | 占用了厨师多少精力 | 4.5% | 进程在过去 1 秒内占用的单核 CPU 时间百分比。⚠️ 多核 CPU:一个进程最多可以占用 100%× 核心数(如 4 核 CPU 最高 400%) |
| %MEM | 内存使用率 | 占用了办公室多少空间 | 19.9% | 进程常驻内存 (RES) 占系统总物理内存的百分比 |
| TIME+ | 累计 CPU 使用时间 | 厨师在这个任务上总共花了多久 | 0:14.07 | 进程自启动以来累计占用 CPU 的时间,精确到百分之一秒(格式:分钟:秒. 百分秒) |
| COMMAND | 进程名 / 命令行 | 任务名称 | gnome-shell | 启动该进程的命令。按c键可以切换显示完整命令行或仅进程名 |
共享内存计算公式:
RES - SHR = 进程独占内存
top 常用快捷键
| 快捷键 | 功能 |
|---|---|
h / ? | 显示帮助 |
M | 按内存使用排序 |
P | 按 CPU 使用排序 |
N | 以 PID 大小排序 |
< | 向前移动列 |
> | 向后移动列 |
z | 彩色显示 |
Z | 设置彩色主题 |
top 实用技巧
# 启动 top,回车立刻刷新,按 z 彩色显示,按 F 通过光标设置列的顺序
top
# 每 1 秒刷新一次(默认是 3 秒)
top -d 1
# 查看指定进程的动态信息
top -d 1 -p 10126
# 同时查看多个进程(查看 10126 和 1 号进程)
top -d 1 -p 10126,1
使用场景:
服务器变慢排查:
top
# 然后按 M 查看内存占用最高的进程
# 或者按 P 查看 CPU 占用最高的进程监控特定服务:
# 先找到 Nginx 的 PID
ps aux | grep nginx
# 然后只监控 Nginx 进程
top -p <nginx_pid>
使用信号控制进程
什么是信号?
信号是 Linux 系统中进程间通信的一种方式。就像你给朋友发微信消息,朋友收到后做出相应的反应。系统也可以通过发送信号来告诉进程该做什么。
常用信号类型
# 列出所有支持的信号
kill -l
kill命令默认发送的就是信号 15 (SIGTERM),所以kill 11854和kill -15 11854是完全等价的。
| 编号 | 信号名 | 说明 | 触发快捷方式 |
|---|---|---|---|
| 1 | SIGHUP | 重新加载配置 | – |
| 2 | SIGINT | 键盘中断 | Ctrl+C |
| 3 | SIGQUIT | 键盘退出 | Ctrl+\ |
| 9 | SIGKILL | 强制终止,无条件 | – |
| 15 | SIGTERM | 正常终止(默认信号) | – |
| 18 | SIGCONT | 继续 | – |
| 19 | SIGSTOP | 暂停 | – |
| 20 | SIGTSTP | 键盘暂停 | Ctrl+Z |
信号 9 与 信号 15 的区别
这是日常运维最容易混淆的地方。
举个例子解释:
信号 15(SIGTERM):你跟朋友说”我走了,你收拾一下厨房”。朋友会把手里的菜炒完,洗好锅,关好煤气,然后离开。这是一种礼貌的终止方式。
信号 9(SIGKILL):你直接把朋友拉出厨房,锅里的菜糊了也不管。这是一种强制终止方式。
示例:信号 9 与 信号 15
# 1. 创建两个文件
touch file1 file2
# 2. 在一个终端打开 vim
vim file1
# 3. 在另一个终端打开 vim
vim file2
# 4. 在第三个终端查询两个 vim 进程
ps aux | grep vim
输出示例:
[root@localhost ~]# ps aux | grep vim
root 11854 0.0 0.5 151532 5060 pts/1 S+ 14:22 0:00 vim file1
root 11855 0.1 0.5 151532 5056 pts/2 S+ 14:23 0:00 vim file2
root 11869 0.0 0.0 112724 988 pts/0 R+ 14:23 0:00 grep --color=auto vim
# 5. 发送信号 15 和信号 9
kill -15 11854 # 正常终止
kill -9 11855 # 强制杀死
观察结果:
- 使用信号 15 的 vim 会正常退出(可能提示保存未保存的内容)
- 使用信号 9 的 vim 会被强制终止(未保存的内容会丢失)
实际应用场景
场景一:Web 服务重新加载配置
# Nginx 重新加载配置,不中断现有连接
kill -1 <nginx_master_pid>
# 或者
nginx -s reload
场景二:终止卡死的程序
# 先尝试正常终止
kill -15 <pid>
# 如果没反应(程序忽略了信号 15),再强制终止
kill -9 <pid>
最佳实践:永远先尝试信号 15,只有当进程无响应时才使用信号 9。因为信号 9 无法被进程捕获和处理,进程没有机会清理资源和保存数据。
进程优先级 nice
简介
Linux 通过时间片技术来实现多任务调度。每个 CPU 在一个时间点上只能处理一个进程,通过时间片轮转,让多个程序”同时”运行。
举个例子:
想象一个幼儿园老师(CPU)要照顾多个小朋友(进程)。老师不能一直盯着一个小朋友,而是要轮流关注每个人。nice 值就是决定老师多关注哪个小朋友:
- nice 值小(优先级高):老师多花时间关注这个小朋友
- nice 值大(优先级低):老师少花点时间关注这个小朋友
优先级范围
| 特性 | 说明 |
|---|---|
| Nice 值范围 | -20 ~ +19 |
| Nice 值越大 | 优先级越低(例如 +19) |
| Nice 值越小 | 优先级越高(例如 -20) |
记忆技巧:nice 在英语中是”好的、友善的”意思。一个进程越”nice”(nice 值越大),就意味着它越”客气”,把资源让给别人,所以优先级越低。
两种优先级显示
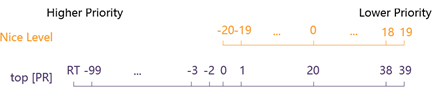
在 top 中显示的优先级有两个:
| 类型 | 说明 |
|---|---|
| NI | 实际 nice 值(-20 ~ +19) |
| PR | 将 nice 级别显示为映射到更大优先级队列(-20 映射到 0,+19 映射到 39) |
换算公式:PR = NI + 20
查看进程的 nice 级别
# 按 nice 值降序显示
ps axo pid,command,nice --sort=-nice
输出示例:
PID COMMAND NI
32 [khugepaged] 19
6600 /usr/sbin/alsactl -s -n 19 19
8602 /usr/libexec/tracker-extrac 19
8606 /usr/libexec/tracker-miner- -
8612 /usr/libexec/tracker-miner- 19
8618 /usr/libexec/tracker-miner- -
31 [ksmd] 5
启动具有不同 nice 级别的进程
sleep 6000这个命令作用为让你的终端睡眠6000秒,这样会占着你的终端无法输入。&可以将这个命令放到后台运行,当你用&将命令放到后台运行时,Shell 会自动打印该后台进程的作业号和PID。
# 默认情况:启动进程时会继承父进程的 nice 级别,默认为 0
# 手动指定 nice 级别启动进程
nice -n -5 sleep 6000 &
nice -n -10 sleep 7000 &
# 查看 nice 值
ps axo command,pid,nice | grep sleep
输出示例:
[root@localhost ~]# nice -n -5 sleep 6000 &
[1] 12545
[root@localhost ~]# nice -n -10 sleep 7000 &
[2] 12546
[root@localhost ~]# ps axo command,pid,nice | grep sleep
sleep 60 12415 0
sleep 6000 12545 -5
sleep 7000 12546 -10
grep --color=auto sleep 12548 0
[root@localhost ~]#
更改现有进程的 nice 级别
# 1. 创建一个后台进程
[root@localhost ~]# sleep 7000 &
[4] 12568
# 2. 修改它的 nice 值
[root@localhost ~]# renice -20 12568
12568 (进程 ID) 旧优先级为 0,新优先级为 -20
实际应用场景
场景一:降低备份任务的优先级
# 夜间备份数据时,降低备份进程的优先级,不影响白天业务
nice -n 19 tar -czf backup.tar.gz /data &
场景二:提高关键服务的优先级
# 提高数据库进程的优先级
renice -10 -p <mysql_pid>
作业控制 jobs(了解)
作业控制是一个命令行功能,也叫后台运行。
核心概念
| 术语 | 缩写 | 说明 |
|---|---|---|
| Foreground | fg | 前台进程:在终端中运行的命令,占领终端 |
| Background | bg | 后台进程:没有控制终端,不需要终端交互,看不见但在运行 |
生活比喻:
- 前台进程:就像你在跟朋友面对面聊天,你的注意力完全在聊天上,做不了其他事情。
- 后台进程:就像你给朋友发了消息,然后你可以继续做自己的事情,等朋友回复了再处理。
后台程序控制示例
1. 观察”占领前台”现象
# 运行 sleep,当前终端无法输入(大部分命令无效)
sleep 2000
# 使用 Ctrl+C 终止进程
现象解释:当你运行 sleep 2000 后,终端会被”占领”,你无法输入新的命令。这就像你正在排队等咖啡,在轮到你之前你不能离开队伍去做别的事情。
2. 运行后台程序
# 在后台运行(添加 &)
sleep 3000 &
输出示例:
[1] 8895
[1]是作业编号,8895是进程 PID
3. 查询所有进程
ps aux | grep sleep
输出示例:
root 8895 0.0 0.0 100900 556 pts/0 S 12:13 0:00 sleep 3000
4. 查看后台作业
jobs
输出示例:
[1]+ Running sleep 3000 &
+和-表示使用fg时默认调动至前台的进程:
+表示默认作业-表示第二个默认作业
5. 调动后台程序至前台
# 将作业 1 调回到前台
fg 1
6. 暂停前台进程并放入后台
# 先在前台运行一个程序
sleep 3000
# 然后按 Ctrl+Z 暂停
# 输出:[1]+ Stopped sleep 3000
# 查看作业
jobs
# 输出:[1]+ Stopped sleep 3000
# 让暂停的作业在后台继续运行
bg 1
7. 终止后台作业
# 杀死作业序号为 1 的后台程序
kill %1
重要区别:
kill 1→ 终止 PID 为 1 的进程(通常是 systemd)kill %1→ 终止作业序号为 1 的后台程序
常用命令总结
| 命令 | 功能 |
|---|---|
command & | 后台运行程序 |
jobs | 查看后台作业 |
fg [作业号] | 将作业调到前台 |
bg [作业号] | 让暂停的作业在后台继续运行 |
kill %作业号 | 停止后台作业 |
Ctrl+Z | 暂停当前前台进程 |
Ctrl+C | 终止当前前台进程 |
虚拟文件系统 proc
简介
/proc 是一个虚拟文件系统,用于采集服务器自身的内核和进程运行状态信息。
特点:
- 它不在磁盘上,而是在内存中
- 里面的文件不是真正的文件,而是内核提供的数据接口
- 当你读取这些”文件”时,内核会实时生成数据返回给你
简单的说:
把 /proc 想象成医院的”体检中心”。你不需要去拍片、抽血,只要读取这些”文件”,就能实时了解系统的”健康状况”。
查看 CPU 信息
cat /proc/cpuinfo
常用信息:
# 查看 CPU 核心数
grep -c "processor" /proc/cpuinfo
# 查看 CPU 型号
grep "model name" /proc/cpuinfo | head -1
查看内存信息
less /proc/meminfo
常用信息:
# 查看总内存
grep "MemTotal" /proc/meminfo
# 查看可用内存
grep "MemAvailable" /proc/meminfo
查看内核启动参数
cat /proc/cmdline
查看特定进程信息
# 查看 PID 为 1 的进程信息
ls /proc/1/
cat /proc/1/status
cat /proc/1/cmdline
# 查看进程打开的文件
ls /proc/1/fd/
了解相关的情景
常见问题
Q1:什么是僵尸进程?如何处理?
什么是僵尸进程?
僵尸进程是已经执行完毕,但其父进程还没有回收它资源的进程。
生活比喻:
就像你吃完饭离开了餐厅,但服务员还没有来收拾桌子。桌子(进程资源)还占用着,但已经没有人(进程)在使用它了。
查看僵尸进程:
ps aux | grep Z
# 或者
ps -eo pid,ppid,stat,cmd | grep Z
处理方法:
找到僵尸进程的父进程:
ps -eo pid,ppid,stat,cmd | grep Z给父进程发送信号,让它回收子进程:
kill -17 <父进程PID> # SIGCHLD 信号如果父进程不响应,可以杀死父进程:
kill -15 <父进程PID>
# 如果还不行
kill -9 <父进程PID>
Q2:如何杀死所有同名进程?
# 方法一:使用 killall
killall nginx
# 方法二:使用 pkill
pkill -9 nginx
# 方法三:使用 ps + awk + kill
ps aux | grep nginx | grep -v grep | awk '{print $2}' | xargs kill -9
Q3:服务器负载很高怎么办?
排查步骤:
查看负载和进程状态:
top
# 查看 load average 和运行中的进程数找到占用资源最多的进程:
# 按 CPU 排序
ps aux --sort=-%cpu | head -10
# 按内存排序
ps aux --sort=-%mem | head -10查看是否有僵尸进程:
ps aux | grep Z查看 I/O 等待:
top
# 查看 wa(wait)值,如果很高说明磁盘 I/O 是瓶颈
最佳实践
优雅地终止进程:
- 先使用
kill -15 <pid>(正常终止) - 等待几秒,如果进程没有退出,再使用
kill -9 <pid>(强制终止)
- 先使用
不要随意杀死系统进程:
- PID 小于 100 的进程通常是系统关键进程
- 特别是 PID=1(systemd),绝对不能杀死
使用 nice 值合理分配资源:
- 重要的服务(如数据库)设置较低的 nice 值(高优先级)
- 后台任务(如备份、日志轮转)设置较高的 nice 值(低优先级)
定期检查僵尸进程:
# 将这条命令加入 crontab 定期检查
ps aux | awk '$8 ~ /Z/ {print $0}'使用 top 批处理模式生成报告:
# 生成 3 次 top 快照到文件
top -b -n 3 > top_report.txt
总结
通过本章节的学习,你应该掌握了:
- 理解进程的概念、生命周期和状态
- 使用
ps静态查看进程 - 使用
top动态监控进程 - 使用
kill发送信号控制进程 - 使用
nice和renice调整进程优先级 - 使用
jobs、fg、bg管理后台作业 - 通过
/proc文件系统查看系统信息
学习建议:进程管理是 Linux 运维的核心技能之一,建议在自己的虚拟机上多练习这些命令,通过实际操作来加深理解。
